
انویدیا ادعا میکند ارتقاء نرمافزاری و سختافزاری به Blackwell Ultra GB300 اجازه میدهد تا بر بنچمارکهای MLPerf مسلط شود
انویدیا با استفاده از سیستم مقیاس رک نسل جدید خود، Blackwell Ultra GB300 NVL72، رکوردهای خود را در بنچمارکهای MLPerf شکست. این شرکت ادعا میکند که در تستهای DeepSeek R1، عملکرد استنتاج را تا ۴۵ درصد نسبت به پلتفرم GB200 مبتنی بر Blackwell افزایش داده است. انویدیا با ترکیب بهبودهای سختافزاری و بهینهسازیهای نرمافزاری، در اجرای طیف وسیعی از مدلها جایگاه برتر را کسب کرده و پیشنهاد میکند که این موضوع باید یک ملاحظه اصلی برای هر توسعهدهندهای باشد که در حال ساخت «کارخانههای هوش مصنوعی» است، زیرا میتواند منجر به افزایش قابل توجهی در تولید درآمد شود.
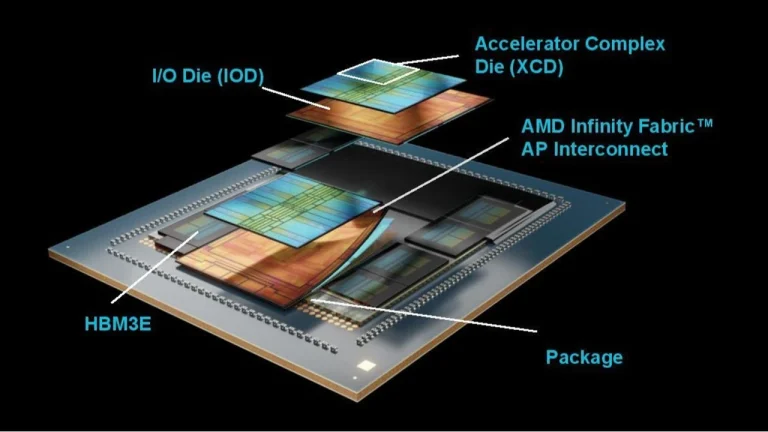
معماری Blackwell انویدیا در قلب کارتهای گرافیک سری RTX 50 نسل جدید این شرکت قرار دارد که بهترین عملکرد را برای بازی ارائه میدهند، حتی اگر سری RX 9000 ایامدی به طور قابل بحثی ارزش خرید بهتری داشته باشد. اما این معماری همچنین زیربنای پشتههای بزرگ GPU قدرتبخش هوش مصنوعی مانند پلتفرم GB200 است که در طیف وسیعی از مراکز داده در سراسر جهان برای تامین انرژی برنامههای هوش مصنوعی نسل بعدی در حال ساخت است. Blackwell Ultra GB300 نسخه بهبود یافته آن با عملکردی حتی بیشتر است و انویدیا اکنون آن را با رکوردهای چشمگیر MLPerf آزمایش کرده است.
آخرین نسخه بنچمارک MLPerf شامل تست عملکرد استنتاج با استفاده از مدلهای DeepSeek R1، Llama 3.1 405B، Llama 3.1 8B و Whisper است و GB300 NVL72 در همه آنها درخشید. انویدیا ادعا میکند که هنگام اجرای مدل DeepSeek، ۴۵ درصد افزایش عملکرد نسبت به GB200 و تا پنج برابر عملکرد GPUهای قدیمیتر Hopper را دارد – اگرچه انویدیا اشاره میکند که این نتایج مقایسهای از منابع شخص ثالث تایید نشده به دست آمدهاند.


بخشی از این بهبودهای عملکردی از هستههای تنسور توانمندتر مورد استفاده در Blackwell Ultra ناشی میشود، به طوری که انویدیا ادعا میکند «۲ برابر شتاب لایه توجه و ۱.۵ برابر FLOPS محاسباتی هوش مصنوعی بیشتر» را ارائه میدهد. با این حال، این امر با طیف وسیعی از بهبودها و بهینهسازیهای نرمافزاری مهم نیز امکانپذیر شده است.
انویدیا فرمت NVFP4 خود را به طور گسترده به عنوان بخشی از این بنچمارکها به کار گرفت، که وزنهای DeepSeek R1 را به گونهای کوانتیزه کرد که اندازه کلی مدل را کاهش داده و به Blackwell Ultra اجازه میدهد تا محاسبات را برای توان عملیاتی بالاتر، ضمن حفظ دقت، تسریع کند.
برای سایر بنچمارکها، مانند مدل بزرگتر Llama 3.1 405B، انویدیا توانست مدل را به طور همزمان در چندین GPU «خرد» کند، که توان عملیاتی بالاتری را امکانپذیر میسازد و در عین حال استانداردهای تاخیر را حفظ میکند. این امر تنها به دلیل ساختار NVLink با پهنای باند ۱.۸ ترابایت بر ثانیه بین هر یک از ۷۲ GPU آن، برای پهنای باند کلی ۱۳۰ ترابایت بر ثانیه، امکانپذیر بود.
همه اینها بخشی از رویکرد انویدیا برای Blackwell Ultra است که آن را به عنوان یک عامل تحولآفرین اقتصادی برای توسعه «کارخانههای هوش مصنوعی» معرفی میکند. استنتاج بیشتر از طریق بهینهسازیهای سختافزاری و نرمافزاری، GB300 را به پلتفرمی با پتانسیل سودآوری بیشتر در ایده انویدیا از آینده توکنسازی شده بارهای کاری مراکز داده تبدیل میکند. با شروع عرضه GB300 در این ماه، زمانبندی این نتایج بنچمارک جدید تصادفی به نظر نمیرسد.
- کولبات
- شهریور 19, 1404
- 65 بازدید






