اوپنایآی مدل جدید GPT-5.3-Codex-Spark را بر روی تراشههای Cerebras Systems عرضه کرده است که اولین استقرار تولیدی این شرکت بر روی سختافزاری خارج از پشته اصلی انویدیا را نشان میدهد. این مدل، نسخهای کممصرف از Codex است که برای کارهای کدنویسی تعاملی و سریع بهینهسازی شده و در ابتدا برای مشترکین ChatGPT Pro در دسترس است. سختافزار Cerebras با موتور مقیاس ویفر نسل سوم خود، با هستههای هوش مصنوعی فراوان و حافظه روی تراشه، برای به حداقل رساندن تأخیر در بارهای کاری استنتاج تعاملی طراحی شده است.
این اقدام، اگرچه جایگزین نقش انویدیا در آموزش نمیشود، اما یک رده اختصاصی برای پاسخگویی سریع فراهم میکند. اوپنایآی همچنین قراردادهایی با AMD برای ۶ گیگاوات تراشه و با Broadcom برای توسعه شتابدهندههای هوش مصنوعی سفارشی امضا کرده است که نشاندهنده استراتژی تنوعبخشی به اکوسیستم سختافزاری هوش مصنوعی خود است. با این حال، اوپنایآی بر ادامه همکاری قوی با انویدیا تأکید کرده و آن را ستون فقرات پشته آموزش و استنتاج خود میداند.
برادکام قراردادی ۱۰ میلیارد دلاری برای تامین سختافزار سفارشی مرکز داده هوش مصنوعی با یک مشتری نامعلوم امضا کرده است که گمان میرود OpenAI باشد. OpenAI قصد دارد از میلیونها پردازنده هوش مصنوعی سفارشی (XPU) برای بارهای کاری استنتاجی خود استفاده کند. این سختافزار، شامل شتابدهندهها و تراشههای شبکه، به عنوان بلوکهای ساختمانی برای زیرساختهای هوش مصنوعی در مقیاس بزرگ عمل میکند. برادکام تایید کرده که سختافزار “واجد شرایط” است و سفارشهای تولیدی صادر شدهاند و خرید تجاری آغاز شده است.
تحویل این سختافزار در سه ماهه سوم سال ۲۰۲۶ پیشبینی میشود. پردازنده سفارشی OpenAI احتمالاً از معماری آرایه سیستولیک، حافظه HBM و فناوری فرآیند ۳ نانومتری TSMC استفاده میکند. این سرمایهگذاری عظیم، نشاندهنده تغییر استراتژیک OpenAI به سمت زیرساخت داخلی با سیلیکون سفارشی Broadcom است. هدف این اقدام، کنترل هزینه و بهینهسازی استنتاج است و میتواند اهرم مذاکره با تامینکنندگان را افزایش دهد، هرچند هنوز هیچ تایید رسمی در این خصوص وجود ندارد.
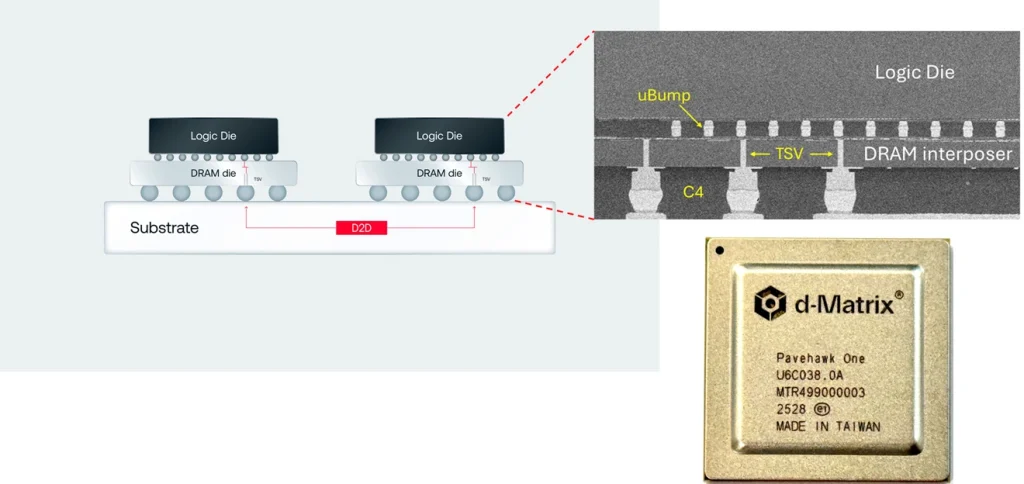
استارتاپ d-Matrix فناوری حافظه سهبعدی پشتهای 3DIMC را معرفی کرده که ادعا میکند در استنتاج هوش مصنوعی (AI inference) تا ۱۰ برابر سریعتر و کارآمدتر از HBM است. این فناوری محاسبات درون حافظهای، گلوگاه حافظه در مدلهای هوش مصنوعی را هدف قرار میدهد. d-Matrix نمونه اولیه Pavehawk را در آزمایشگاه فعال کرده و نسل بعدی Raptor را توسعه میدهد که وعده میدهد HBM را با ۱۰ برابر سرعت بیشتر و ۹۰ درصد مصرف انرژی کمتر در وظایف استنتاج پشت سر بگذارد. این شرکت معتقد است سختافزار اختصاصی برای وظایف خاصی مانند استنتاج هوش مصنوعی ضروری است.
جایگزینی برای HBM از نظر مالی نیز جذاب است. HBM توسط تعداد محدودی از شرکتها تولید شده و قیمت بالایی دارد. با رشد ۳۰ درصدی سالانه بازار HBM تا سال ۲۰۳۰ و افزایش قیمتها، یک جایگزین مقرونبهصرفه برای خریداران هوش مصنوعی جذاب خواهد بود، هرچند حافظههای اختصاصی ممکن است برای برخی مشتریان ریسکپذیر به نظر برسند.