صنعت هوش مصنوعی چین، پس از محدودیتهای پکن بر شتابدهنده H20 انویدیا، به پردازندههای گرافیکی دست دوم و بازسازیشده انویدیا روی آورده است. تقاضا برای کارتهای قدیمیتر A100 و H100 افزایش یافته، زیرا شرکتها آنها را برای سیستمهای استنتاجی سفارشی با کارایی بالا و هزینه کم بازپیکربندی میکنند.
A100 و H100های قدیمیتر، به دلیل نیاز کمتر استنتاج به محاسبات سنگین و اکوسیستم قوی CUDA، همچنان برای وظایف هوش مصنوعی کارآمد هستند. H20 عملکرد هوش مصنوعی بسیار پایینتری ارائه میدهد، که جذابیت آن را برای خریداران چینی کاهش داده است. مراکز داده چین با وجود کاهش قابلیت اطمینان، به خرید بردهای بازسازیشده روی آوردهاند.
این وضعیت، انویدیا را در تنگنا قرار داده؛ بازار خاکستری حاشیه سود را تهدید کرده و پذیرش معماریهای جدیدتر را کند میسازد. همچنین، سرمایهگذاری داخلی پکن در تراشههای بومی را به تأخیر میاندازد. این جریان پردازندههای گرافیکی بازیافتی، پیامدهای ناخواسته کنترلهای صادراتی را آشکار میسازد و نشان میدهد که چگونه سختافزار قدیمیتر انویدیا همچنان به قدرتبخشی به استقرار هوش مصنوعی در آینده ادامه میدهد.
گزارشها نشان میدهد که DeepSeek، پس از آموزش موفق مدل R1 بر روی سختافزار انویدیا، تحت فشار مقامات چینی قرار گرفت تا مدل R2 را با استفاده از سختافزار Huawei Ascend توسعه دهد. اما این اقدام با شکستهای مداوم سختافزاری هواوی مواجه شد که منجر به تأخیر در عرضه R2 گردید. در نتیجه، DeepSeek مجبور شد برای بخش آموزش مدل به تراشههای انویدیا بازگردد، در حالی که از سختافزار هواوی برای عملیات استنتاج (inference) استفاده میکند.
مشکلات اصلی شامل عملکرد ناپایدار، اتصال کندتر بین تراشهها و محدودیتهای کیت ابزار نرمافزاری CANN هواوی بود. با وجود اعزام مهندسان هواوی، DeepSeek نتوانست آموزش کاملاً موفقی را روی پلتفرم Ascend به دست آورد. این ناتوانی، عامل اصلی تأخیر در عرضه R2 از تاریخ برنامهریزی شده آن در ماه می بود.
این رویکرد ترکیبی، یعنی استفاده از انویدیا برای آموزش و هواوی برای استنتاج، از روی ضرورت و نه ترجیح اتخاذ شده است. با توجه به کمبود شدید پردازندههای انویدیا در چین، اطمینان از سازگاری مدلهای هوش مصنوعی با سختافزار داخلی هواوی برای DeepSeek حیاتی است، زیرا بسیاری از مشتریان این شرکت از R2 بر روی پلتفرمهای هواوی استفاده خواهند کرد.
پلتفرم هوش مصنوعی DeepSeek به طور خاص برای سختافزار انویدیا بهینهسازی شده است. این وابستگی، شرکت را در برابر نوسانات عرضه پردازندههای گرافیکی انویدیا آسیبپذیر میکند. بنابراین، تلاش برای کارآمد کردن عملیات استنتاج R2 بر روی پلتفرمهای داخلی مانند Ascend هواوی، گامی مهم برای افزایش انعطافپذیری و استقلال DeepSeek در آینده محسوب میشود.
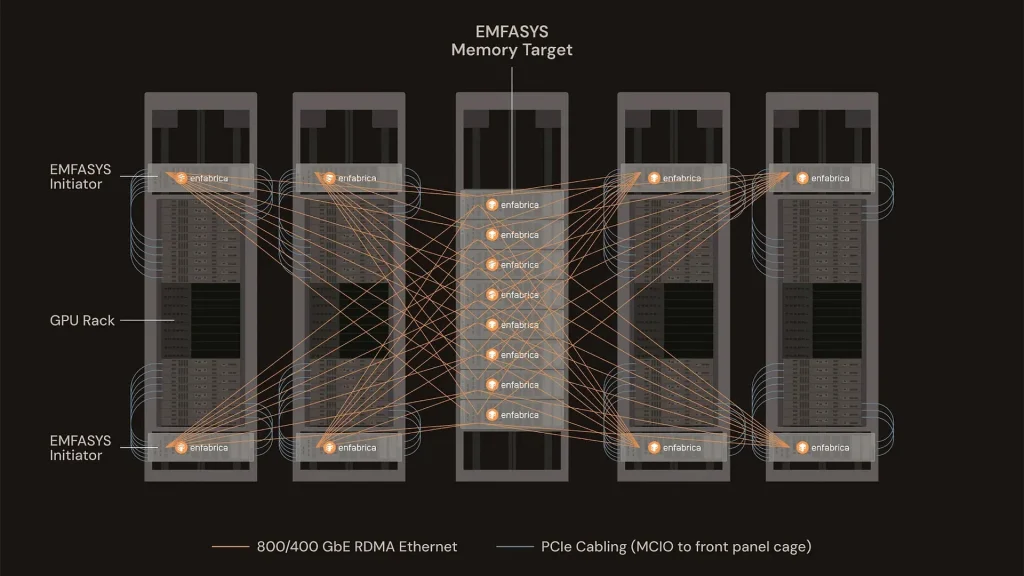
ظرفیت حافظه رم یک گلوگاه مهم برای کاربردهای هوش مصنوعی است. Enfabrica، استارتاپی تحت حمایت انویدیا، سیستم Emfasys را برای حل این مشکل معرفی کرده است. این سیستم نوآورانه امکان افزودن ترابایتها حافظه DDR5 را به هر سروری از طریق اتصال اترنت فراهم میکند. Emfasys به طور خاص برای بارهای کاری استنتاج هوش مصنوعی در مقیاس بزرگ طراحی شده و در حال حاضر با مشتریان منتخب در حال آزمایش است.
Emfasys یک سیستم سازگار با رک است که بر پایه تراشه SuperNIC ACF-S با پهنای باند ۳.۲ ترابیت بر ثانیه ساخته شده و تا ۱۸ ترابایت حافظه DDR5 را با CXL متصل میکند. سرورهای GPU از طریق پورتهای اترنت ۴۰۰G یا ۸۰۰G و با استفاده از RDMA به این مجموعه حافظه دسترسی پیدا میکنند. انتقال دادهها با تأخیر بسیار کم و بدون کپی، از طریق پروتکل CXL.mem انجام میشود. استقرار این سیستم آسان است و نیازی به تغییرات معماری عمده ندارد.
این فناوری نیازهای فزاینده حافظه در هوش مصنوعی مدرن (مانند پرامپتهای طولانی و پنجرههای متنی بزرگ) را برطرف کرده و فشار را از روی حافظه HBM گرانقیمت متصل به GPU برمیدارد. با Emfasys، اپراتورهای مراکز داده میتوانند حافظه سرورهای هوش مصنوعی را به صورت انعطافپذیر گسترش دهند. Enfabrica ادعا میکند که این راهحل میتواند کارایی را افزایش داده، استفاده از منابع را بهینه کند و هزینههای کلی زیرساخت را کاهش دهد. به طور خاص، این تنظیمات میتواند هزینه تولید هر توکن هوش مصنوعی را تا ۵۰٪ در سناریوهای پرکاربرد کاهش دهد.