
بنچمارک هوش مصنوعی InferenceMax پشتههای نرمافزاری، کارایی و TCO را آزمایش میکند
پوشش خبری پیرامون هوش مصنوعی تقریباً همیشه بر معاملاتی تمرکز دارد که صدها میلیارد دلار را جابجا میکنند، یا بر آخرین پیشرفتهای سختافزاری در دنیای GPU یا مراکز داده. با این حال، تلاشهای بنچمارکینگ تقریباً منحصراً بر سیلیکون متمرکز بودهاند، و این همان چیزی است که SemiAnalysis قصد دارد با مجموعه بنچمارکینگ هوش مصنوعی InferenceMax متنباز خود به آن بپردازد. این مجموعه کارایی بسیاری از اجزای پشتههای نرمافزاری هوش مصنوعی را در سناریوهای استنتاجی واقعی (زمانی که مدلهای هوش مصنوعی واقعاً در حال “اجرا” هستند و نه آموزش) اندازهگیری میکند و نتایج را در داشبورد زنده InferenceMax منتشر میکند.
InferenceMax تحت مجوز Apache 2.0 منتشر شده است و عملکرد صدها ترکیب سختافزاری و نرمافزاری شتابدهنده هوش مصنوعی را به صورت انتشار مداوم اندازهگیری میکند و هر شب نتایج جدیدی را با نسخههای اخیر نرمافزار به دست میآورد. همانطور که پروژه بیان میکند، بنچمارکهای موجود در نقاط زمانی ثابتی انجام میشوند و لزوماً نشان نمیدهند که نسخههای فعلی چه قابلیتهایی دارند؛ همچنین تکامل (یا حتی پسرفت) پیشرفتهای نرمافزاری را در کل یک پشته هوش مصنوعی با درایورها، کرنلها، فریمورکها، مدلها و سایر اجزا برجسته نمیکنند.
این بنچمارک به گونهای طراحی شده است که تا حد امکان بیطرف باشد و کاربردهای دنیای واقعی را شبیهسازی کند. به جای تمرکز صرف بر عملکرد مطلق، معیارهای InferenceMax سعی میکنند به عدد جادویی که پروژهها به آن اهمیت میدهند برسند: TCO (هزینه کل مالکیت)، بر حسب دلار در هر میلیون توکن. به عنوان یک سادهسازی، “توکن” معیاری برای دادههای تولید شده توسط هوش مصنوعی است. معیار عملکرد پایه، توکن در ثانیه برای GPU یا کاربر است که هر معیار بسته به تعداد درخواستهایی که در هر لحظه ارائه میشود، متفاوت است.
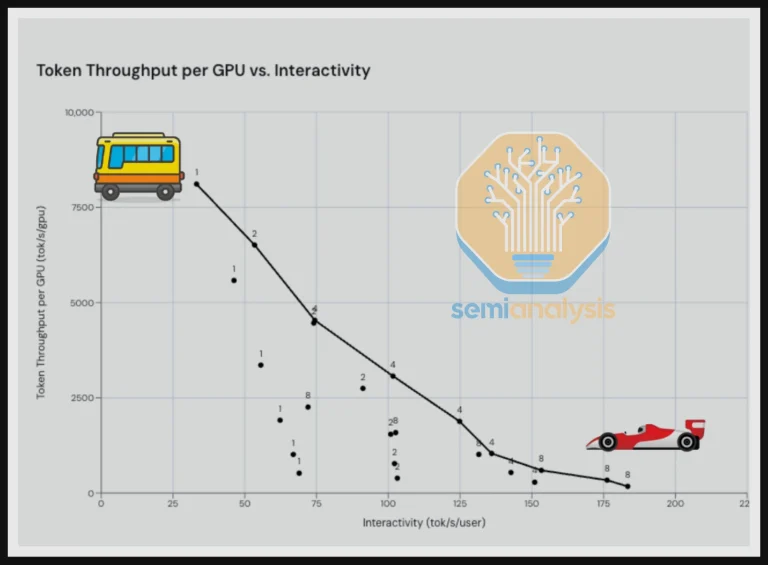
بر اساس ضربالمثل قدیمی “سریع، بزرگ یا ارزان — دو مورد را انتخاب کنید”، توان عملیاتی بالا (اندازهگیری شده بر حسب توکن/ثانیه/GPU)، به معنای استفاده بهینه از GPU، با ارائه خدمات به چندین مشتری به طور همزمان به بهترین وجه به دست میآید، زیرا استنتاج LLM بر ضرب ماتریس متکی است که به نوبه خود از دستهبندی بسیاری از درخواستها بهره میبرد. با این حال، ارائه خدمات به بسیاری از درخواستها به طور همزمان، زمانی را که GPU میتواند به یک درخواست اختصاص دهد، کاهش میدهد، بنابراین دریافت خروجی سریعتر (مثلاً در یک مکالمه چتبات) به معنای افزایش تعاملپذیری (اندازهگیری شده بر حسب توکن/ثانیه/کاربر) و کاهش توان عملیاتی است. به عنوان مثال، اگر تا به حال دیدهاید که ChatGPT طوری پاسخ میدهد که انگار لکنت زبان شدیدی دارد، میدانید چه اتفاقی میافتد وقتی توان عملیاتی در مقابل تعاملپذیری بیش از حد بالا تنظیم شود.
همانند هر سناریوی از نوع گلدلاک، تعادل کاملی بین این دو معیار برای یک تنظیمات عمومی وجود دارد. ارقام تنظیمات ایدهآل در منحنی مرز پارتو (Pareto Frontier Curve) قرار میگیرند، یک منطقه خاص در نموداری که توان عملیاتی را در مقابل تعاملپذیری ترسیم میکند و به راحتی توسط نمودار زیر نشان داده شده است. از آنجایی که GPUها بر اساس هزینه دلار در ساعت هنگام در نظر گرفتن قیمت و مصرف برق (یا هنگام اجاره) خریداری میشوند، بهترین GPU برای هر سناریوی خاص لزوماً سریعترین نیست — بلکه کارآمدترین خواهد بود.
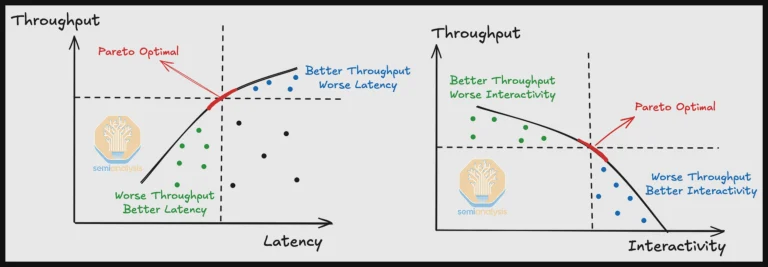
InferenceMax اشاره میکند که موارد با تعاملپذیری بالا گرانتر از موارد با توان عملیاتی بالا هستند، اگرچه به طور بالقوه سودآورترند، زیرا به طور همزمان به کاربران بیشتری خدمات میدهند. بنابراین، تنها معیار واقعی برای ارائهدهندگان خدمات، TCO است که بر حسب دلار در هر میلیون توکن اندازهگیری میشود. InferenceMax تلاش میکند این رقم را برای سناریوهای مختلف، از جمله خرید و مالکیت GPU در مقابل اجاره آنها، تخمین بزند.
توجه به این نکته مهم است که صرفاً نگاه کردن به نمودارهای عملکرد برای یک GPU مشخص به همراه پشته نرمافزاری مرتبط با آن، تصویر خوبی از بهترین گزینه به شما نمیدهد، اگر تمام معیارها و سناریوی استفاده مورد نظر در نظر گرفته نشوند. علاوه بر این، InferenceMax باید نشان دهد که چگونه تغییرات در پشته نرمافزاری، به جای تراشهها، بر تمام معیارهای فوق و در نتیجه TCO تأثیر میگذارد.
به عنوان مثالهای عملی، InferenceMax اشاره میکند که MI335X شرکت AMD در TCO واقعاً با B200 بزرگ انویدیا رقابتی است، حتی با وجود اینکه دومی بسیار سریعتر است. از سوی دیگر، به نظر میرسد کرنلهای FP4 (فرمت ممیز شناور 4 بیتی) AMD جای بهبود دارند، زیرا سناریوها/مدلهایی که به این محاسبات وابسته هستند، عمدتاً در حوزه تراشههای انویدیا قرار دارند.
برای انتشار نسخه 1.0 خود، InferenceMax ترکیبی از شتابدهندههای GB200، NVL72، B200، H200 و H100 انویدیا، و همچنین Instinct MI355X، MI325X و MI300X شرکت AMD را پشتیبانی میکند. این پروژه اشاره میکند که انتظار دارد در ماههای آینده پشتیبانی از واحدهای Tensor گوگل و AWS Trainium را اضافه کند. بنچمارکها هر شب از طریق GitHub’s action runners اجرا میشوند. از هر دو شرکت AMD و Nvidia مجموعههای پیکربندی واقعی برای GPUها و پشته نرمافزاری درخواست شد، زیرا اینها را میتوان به هزاران روش مختلف تنظیم کرد.
در مورد همکاری با فروشندگان، InferenceMax از بسیاری از افراد در سراسر فروشندگان اصلی و چندین ارائهدهنده میزبانی ابری که با این پروژه همکاری کردند، تشکر میکند، برخی حتی اشکالات را یک شبه برطرف کردند. این پروژه همچنین چندین اشکال را در تنظیمات انویدیا و AMD کشف کرد که نشاندهنده سرعت بالای توسعه و استقرار تنظیمات شتابدهنده هوش مصنوعی است.
این همکاری منجر به پچهایی برای ROCm شرکت AMD (معادل CUDA انویدیا) شد، و InferenceMax اشاره کرد که AMD باید بر ارائه پیکربندیهای پیشفرض بهتر به کاربران خود تمرکز کند، زیرا گزارش شده است که پارامترهای زیادی برای تنظیم جهت دستیابی به عملکرد بهینه وجود دارد. در سمت انویدیا، این پروژه با درایورهای تازه منتشر شده Blackwell با مشکلاتی روبرو شد و در سناریوهای بنچمارکینگ که نمونهها را به سرعت بالا و پایین میآوردند، مشکلاتی در مورد مقداردهی اولیه/پایان یافت که آشکار شد.
اگر علاقه بیشتری به این حوزه دارید، باید اعلامیه و گزارش InferenceMax را بخوانید. این یک مطالعه سرگرمکننده است و چالشهای فنی مواجه شده را به شیوهای طنزآمیز شرح میدهد.
- کولبات
- مهر 22, 1404
- 50 بازدید






