
پردازنده گرافیکی جدید CPX انویدیا با هدف تغییر بازی در استنتاج هوش مصنوعی
پردازندههای گرافیکی دیتاسنتر انویدیا به دلیل عملکرد بالا، استفاده از HBM با پهنای باند فوقالعاده، اتصالات سریع در مقیاس رک، و پشته نرمافزاری کامل CUDA، به استاندارد طلایی برای آموزش و استنتاج هوش مصنوعی تبدیل شدهاند. با این حال، با فراگیرتر شدن هوش مصنوعی و بزرگتر شدن مدلها (به ویژه در هایپراسکیلرها)، منطقی است که انویدیا پشته استنتاج خود را تفکیک کرده و از پردازندههای گرافیکی تخصصی برای تسریع فاز زمینه (context phase) استنتاج استفاده کند؛ فازی که مدل باید میلیونها توکن ورودی را به طور همزمان پردازش کند تا خروجی اولیه را بدون استفاده از پردازندههای گرافیکی گرانقیمت و پرمصرف با حافظه HBM تولید کند. این ماه، این شرکت رویکرد خود را برای حل این مشکل با Rubin CPX— Content Phase aXcelerator — اعلام کرد که در کنار پردازندههای گرافیکی Rubin و پردازندههای مرکزی Vera قرار خواهد گرفت تا بارهای کاری خاص را تسریع کند.

استنتاج با زمینه طولانی چیست؟
مدلهای زبان بزرگ مدرن (مانند GPT-5، Gemini 2 و Grok 3) بزرگتر، در استدلال توانمندتر و قادر به پردازش ورودیهایی هستند که قبلاً غیرممکن بودند، که کاربران نهایی به طور گسترده از آنها استفاده میکنند. این مدلها نه تنها از نظر اندازه بزرگتر هستند، بلکه از نظر معماری نیز توانایی بیشتری در استفاده مؤثر از پنجرههای زمینه گسترده دارند. استنتاج در مدلهای هوش مصنوعی در مقیاس بزرگ به طور فزایندهای به دو بخش تقسیم میشود: یک فاز اولیه زمینه فشرده محاسباتی که ورودی را برای تولید اولین توکن خروجی پردازش میکند، و یک فاز دوم که توکنهای اضافی را بر اساس زمینه پردازش شده تولید میکند.
همانطور که مدلها به سیستمهای عاملمحور (agentic systems) تکامل مییابند، استنتاج با زمینه طولانی برای فعال کردن استدلال گام به گام، حافظه پایدار در طول وظایف، گفتگوی چند مرحلهای منسجم، و توانایی برنامهریزی و بازبینی بر روی ورودیهای گسترده ضروری میشود، زیرا در غیر این صورت این قابلیتها توسط پنجرههای زمینه محدود میشوند. شاید مهمترین عاملی که باعث اهمیت استنتاج با زمینه طولانی میشود، تنها به این دلیل نیست که مدلها میتوانند آن را انجام دهند، بلکه به این دلیل است که کاربران به هوش مصنوعی برای تحلیل اسناد بزرگ، پایگاههای کد، یا تولید ویدئوهای طولانی نیاز دارند.
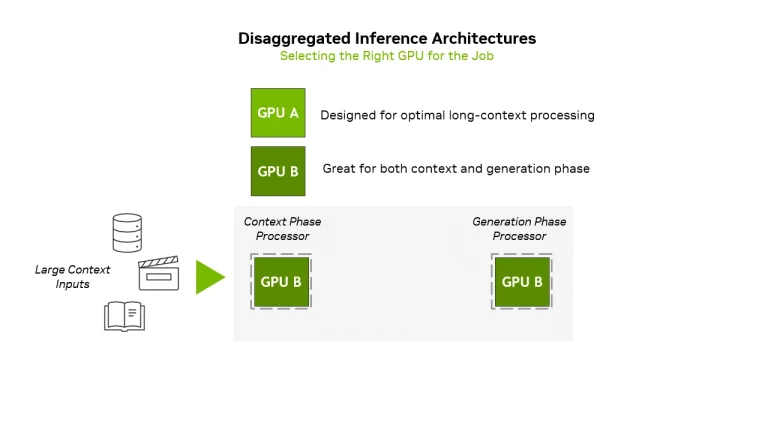
این نوع استنتاج چالشهای متمایزی را برای سختافزار ایجاد میکند. فاز زمینه استنتاج — جایی که مدل کل ورودی را قبل از تولید هر خروجی میخواند و کدگذاری میکند — محدود به محاسبات است و برای تولید بارهای کاری زمینه با بیش از 1 میلیون توکن، به توان عملیاتی محاسباتی بسیار بالا، حافظه فراوان (اما نه لزوماً پهنای باند حافظه فراوان)، و مکانیزمهای توجه بهینه (که وظیفه توسعهدهندگان مدل است) برای حفظ عملکرد در طول توالیهای طولانی نیاز دارد. پردازندههای گرافیکی سنتی دیتاسنتر دارای حافظه HBM زیادی هستند و در حالی که میتوانند چنین بارهای کاری را مدیریت کنند، استفاده از آنها برای این کار بسیار کارآمد نیست. بنابراین، انویدیا قصد دارد از پردازندههای گرافیکی Rubin CPX با 128 گیگابایت GDDR7 داخلی برای فاز زمینه استفاده کند.
در طول فاز دوم، مدل توکنهای خروجی را یکی یکی با استفاده از زمینه کدگذاری شده از فاز اول تولید میکند. این مرحله محدود به پهنای باند حافظه و اتصالات است و نیاز به دسترسی سریع به توکنهای قبلاً تولید شده و کشهای توجه دارد. پردازندههای گرافیکی سنتی دیتاسنتر — مانند Blackwell Ultra (B300 288GB HBM3E) یا Rubin (288GB HBM4) — این کار را با استریم و بهروزرسانی توالیهای توکن در زمان واقعی به طور کارآمد انجام میدهند.
با Rubin CPX آشنا شوید
برای پاسخگویی به نیازهای نوظهور، انویدیا سختافزار تخصصی — پردازنده گرافیکی Rubin CPX — را به طور خاص برای استنتاج با زمینه طولانی طراحی کرده است.
کارت شتابدهنده Rubin CPX بر اساس معماری Rubin انویدیا ساخته شده است، تا 30 پتافلاپس توان عملیاتی محاسباتی NVFP4 (که بسیار زیاد است، زیرا Rubin R100 ‘بزرگ’ با دو چیپلت 50 پتافلاپس NVFP4 ارائه میدهد) را ارائه میدهد و با 128 گیگابایت حافظه GDDR7 عرضه میشود. این پردازنده همچنین دارای شتابدهنده توجه سختافزاری (که شامل سختافزار ضرب ماتریس اضافی است)، که برای استنتاج با زمینه طولانی بدون افت سرعت بسیار مهم است، و همچنین پشتیبانی سختافزاری برای کدگذاری و کدگشایی ویدئو برای پردازش و تولید ویدئو دارد.
استفاده از GDDR7 یکی از ویژگیهای کلیدی متمایز کننده پردازنده گرافیکی Rubin CPX است. در حالی که GDDR7 پهنای باند به طور قابل توجهی کمتری نسبت به HBM3E یا HBM4 ارائه میدهد، اما توان کمتری مصرف میکند، از نظر هر گیگابایت به طور چشمگیری ارزانتر است و به فناوری بستهبندی پیشرفته گرانقیمت، مانند CoWoS، نیاز ندارد. در نتیجه، نه تنها پردازندههای گرافیکی Rubin CPX ارزانتر از پردازندههای معمولی Rubin هستند، بلکه به طور قابل توجهی کمتر مصرف میکنند که خنکسازی را سادهتر میکند.

نگاهی سریع به تصویر دای پردازنده گرافیکی Rubin CPX انویدیا نشان میدهد که طرحبندی آن شبیه به پردازندههای گرافیکی رده بالا است (تا حدی که حتی پخشکننده حرارت آن شبیه به GB202 است). این ASIC در واقع دارای 16 خوشه پردازش گرافیکی (GPC) است که ظاهراً دارای سختافزار خاص گرافیک (مانند بکاند رستر، واحدهای بافت)، یک کش L2 عظیم، هشت رابط حافظه 64 بیتی، PCIe و موتورهای نمایشگر است. آنچه به نظر میرسد این تراشه ندارد، رابطهایی مانند NVLink است، بنابراین فقط میتوانیم تعجب کنیم که آیا تنها از طریق رابط PCIe با همتایان خود ارتباط برقرار میکند.
فقط میتوانیم تعجب کنیم که آیا Rubin CPX از پردازنده گرافیکی GR102/GR202 (که کارتهای گرافیک نسل بعدی را هم برای مصرفکنندگان و هم برای حرفهایها تامین خواهد کرد) استفاده میکند، یا این واحد از یک ASIC منحصر به فرد استفاده میکند. از یک طرف، استفاده از پردازنده گرافیکی درجه مشتری برای شتابدهی استنتاج هوش مصنوعی چیزی نیست که قبلاً دیده نشده باشد: GB202 چهار پتافلاپس NVFP4 ارائه میدهد، در حالی که GB200 ده پتافلاپس NVFP4 دارد. از طرف دیگر، بستهبندی تعداد زیادی FPU با قابلیت NVFP4 و شتابدهندههای توجه سختافزاری در یک پردازنده گرافیکی برای گرافیک ممکن است از منظر اندازه دای بهینهترین انتخاب نباشد. اما از طرف دیگر، تولید دو پردازنده تقریباً به اندازه رتیکل با عملکرد مشابه به جای یکی میتواند از منظر هزینهها، تلاش مهندسی و زمانبندی ناکارآمد باشد.
Rubin CPX در کنار پردازندههای گرافیکی Rubin و پردازندههای مرکزی Vera در سیستم Vera Rubin NVL144 CPX کار خواهد کرد، که 8 اگزافلاپس عملکرد NVFP4 (3.6 اگزافلاپس با استفاده از پردازنده گرافیکی ‘بزرگ’ Rubin و 4.4 اگزافلاپس با استفاده از پردازندههای گرافیکی Rubin CPX) و 100 ترابایت حافظه را در یک رک واحد ارائه میدهد. درست مانند سایر محصولات در مقیاس رک از انویدیا، Vera Rubin NVL144 CPX از اتصال Quantum-X800 InfiniBand یا Spectrum-XGS Ethernet انویدیا همراه با SuperNICهای ConnectX-9 برای اتصال مقیاسپذیر استفاده خواهد کرد.
انویدیا اعلام کرد که معماری Rubin CPX آن محدود به نصبهای کامل رک Vera Rubin NVL144 CPX نیست. این شرکت قصد دارد سینیهای محاسباتی Rubin CPX را برای ادغام در سیستمهای Vera Rubin NVL144 ارائه دهد. با این حال، به نظر میرسد استقرارهای موجود Blackwell قادر به جای دادن سینیهای Rubin CPX برای عملکرد بهینه استنتاج نخواهند بود، اگرچه دلیل آن نامشخص است.
صرف نظر از مقیاس استقرار، Rubin CPX طبق گفته انویدیا، مزایای اقتصادی قابل توجهی را ارائه میدهد. سرمایهگذاری 100 میلیون دلاری در این پلتفرم میتواند به طور بالقوه تا 5 میلیارد دلار درآمد از برنامههای هوش مصنوعی مبتنی بر توکن ایجاد کند، که به معنای بازگشت سرمایه 30 تا 50 برابری است. این ادعا بر اساس توانایی Rubin CPX در کاهش هزینههای استنتاج (زیرا Rubin CPX ارزانتر است و کمتر از R100 کامل مصرف میکند) و گسترش دامنه بارهای کاری هوش مصنوعی قابل اجرا است.
نیازی به طراحی مجدد نرمافزار نیست
در بخش نرمافزار، Rubin CPX به طور کامل توسط اکوسیستم هوش مصنوعی انویدیا، از جمله CUDA، فریمورکها، ابزارها و میکروسرویسهای NIM مورد نیاز برای استقرار راهحلهای هوش مصنوعی در سطح تولید، پشتیبانی میشود. Rubin CPX همچنین از خانواده مدلهای Nemotron، طراحی شده برای استنتاج چندوجهی در سطح سازمانی، پشتیبانی میکند.

توسعهدهندگان مدلها و محصولات هوش مصنوعی نیازی به تقسیم دستی فازهای اول و دوم استنتاج بین پردازندههای گرافیکی برای اجرا بر روی راهحلهای مقیاس رک Rubin NVL144 CPX نخواهند داشت. در عوض، انویدیا پیشنهاد میکند از لایه ارکستراسیون نرمافزاری Dynamo خود برای مدیریت هوشمندانه و تقسیم بارهای کاری استنتاج در انواع مختلف پردازندههای گرافیکی در یک سیستم تفکیک شده استفاده کند. هنگامی که یک پرامپت دریافت میشود، Dynamo به طور خودکار فاز زمینه سنگین محاسباتی را شناسایی کرده و آن را به پردازندههای گرافیکی تخصصی Rubin CPX اختصاص میدهد که برای توجه سریع و پردازش ورودی در مقیاس بزرگ بهینه شدهاند. هنگامی که زمینه کدگذاری شد، Dynamo به طور یکپارچه به فاز تولید منتقل میشود و آن را به پردازندههای گرافیکی غنی از حافظه مانند Rubin استاندارد هدایت میکند که برای تولید خروجی توکن به توکن مناسبتر هستند. انویدیا میگوید که Dynamo میتواند انتقال کش KV را مدیریت کرده و همچنین تأخیر را به حداقل برساند.
مشتریان در صف
چندین شرکت در حال حاضر قصد دارند Rubin CPX را در جریانهای کاری هوش مصنوعی خود ادغام کنند:
- Cursor، یک شرکت نرمافزاری که هوش مصنوعی را برای توسعهدهندگان نرمافزار توسعه میدهد، از Rubin CPX برای پشتیبانی از تولید کد در زمان واقعی و ابزارهای توسعه مشارکتی استفاده خواهد کرد.
- Runway قصد دارد از Nvidia Rubin CPX برای تامین انرژی تولید ویدئو با زمینه طولانی و عاملمحور استفاده کند، که به سازندگان — از هنرمندان انفرادی تا استودیوهای بزرگ — امکان میدهد محتوای سینمایی و جلوههای بصری را با سرعت، واقعگرایی و انعطافپذیری خلاقانه بیشتری تولید کنند.
- Magic، یک شرکت تحقیقاتی هوش مصنوعی که عوامل کدنویسی خودمختار را توسعه میدهد، قصد دارد از Rubin CPX برای پشتیبانی از مدلهایی با پنجرههای زمینه 100 میلیون توکنی استفاده کند، که به آنها امکان میدهد با دسترسی کامل به مستندات، تاریخچه کد و تعاملات کاربر در زمان واقعی کار کنند.
یک پارادایم جدید
از زمان پردازندههای گرافیکی Pascal و Volta حدود یک دهه پیش، پردازندههای گرافیکی انویدیا شتابدهندههای هوش مصنوعی برای پردازندههای مرکزی بودند. با Rubin CPX، این پردازندههای گرافیکی اکنون شتابدهندههای خود را دریافت میکنند. با جداسازی دو مرحله استنتاج — پردازش زمینه و تولید توکن — انویدیا استفاده هدفمندتری از منابع سختافزاری را امکانپذیر میسازد و کارایی را در مقیاس بهبود میبخشد، که نشاندهنده تغییری در نحوه بهینهسازی زیرساخت هوش مصنوعی برای حداکثر کارایی است.
بهینهسازی پردازش استنتاج با زمینه طولانی، نه تنها هزینههای سختافزار و TCO را کاهش میدهد، بلکه پلتفرمهای استنتاج با توان عملیاتی بالا را قادر میسازد که بارهای کاری میلیون توکنی را تحمل کنند. چنین پلتفرمهایی میتوانند مهندسی نرمافزار و سختافزار با کمک هوش مصنوعی پیچیدهتر، تولید ویدئوهای کامل و سایر برنامههای هوش مصنوعی را که امروزه امکانپذیر نیستند، فعال کنند.
اولین پلتفرم مجهز به Rubin CPX انویدیا — Vera Rubin NVL144 CPX — انتظار میرود تا پایان سال 2026 در دسترس باشد.
- کولبات
- مهر 8, 1404
- 37 بازدید






