
آمازون شتابدهنده هوش مصنوعی Trainium3 را عرضه کرد که مستقیماً با Blackwell Ultra در عملکرد FP8 رقابت میکند
آمازون وب سرویسز (AWS) این هفته شتابدهنده نسل بعدی خود، Trainium3، را برای آموزش و استنتاج هوش مصنوعی معرفی کرد. به گفته AWS، پردازنده جدید دو برابر سریعتر از نسل قبلی خود و چهار برابر کارآمدتر است. این امر آن را از نظر هزینه به یکی از بهترین راهحلها برای آموزش و استنتاج هوش مصنوعی تبدیل میکند. در اعداد مطلق، Trainium3 تا 2,517 MXFP8 TFLOPS ارائه میدهد که تقریباً دو برابر کمتر از Blackwell Ultra انویدیا است. با این حال، Trn3 UltraServer شرکت AWS، 144 تراشه Trainium3 را در هر رک جای میدهد و 0.36 اگزافلاپس عملکرد FP8 ارائه میکند، بنابراین با عملکرد NVL72 GB300 انویدیا مطابقت دارد. این یک دستاورد بسیار بزرگ است، زیرا شرکتهای بسیار کمی میتوانند سیستمهای هوش مصنوعی در مقیاس رک انویدیا را به چالش بکشند.
AWS Trainium3
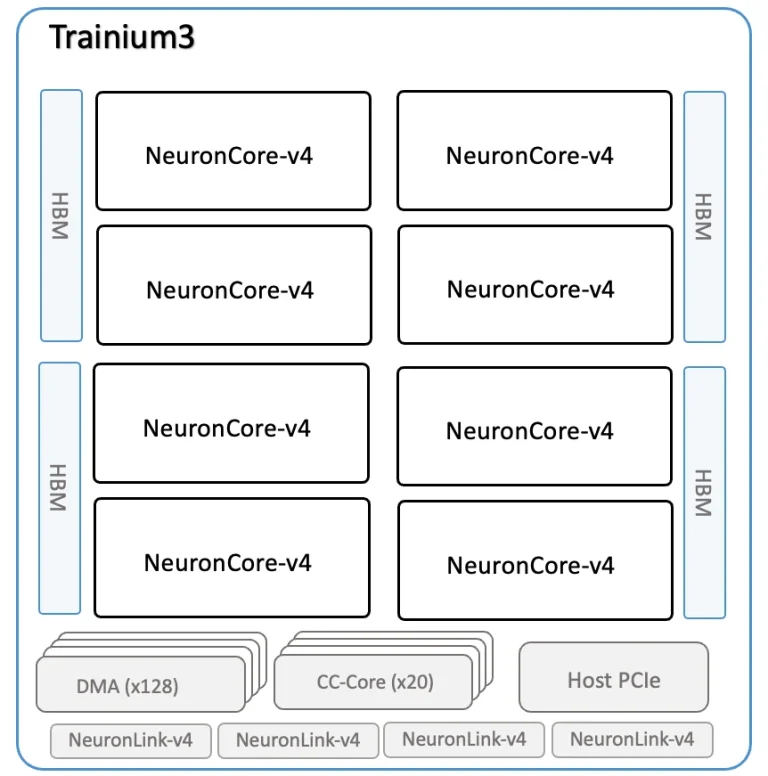
AWS Trainium3 یک شتابدهنده هوش مصنوعی دو چیپلت است که به 144 گیگابایت حافظه HBM3E با استفاده از چهار پشته مجهز شده و پهنای باند حافظه اوج تا 4.9 ترابایت بر ثانیه را فراهم میکند. هر چیپلت محاسباتی، که گفته میشود توسط TSMC با استفاده از فرآیند ساخت 3 نانومتری تولید شده است، شامل چهار هسته NeuronCore-v4 (که در مقایسه با نسلهای قبلی دارای ISA توسعهیافته هستند) است و به دو پشته حافظه HBM3E متصل میشود. این دو چیپلت با استفاده از یک رابط اختصاصی با پهنای باند بالا به هم متصل شدهاند و 128 موتور مستقل حرکت داده سختافزاری (که برای معماری Trainium کلیدی هستند)، هستههای ارتباط جمعی که ترافیک بین تراشهها را هماهنگ میکنند، و چهار رابط NeuronLink-v4 برای اتصال مقیاسپذیر را به اشتراک میگذارند.
یک NeuronCore-v4 چهار بلوک اجرایی را یکپارچه میکند: یک موتور تنسور، یک موتور برداری، یک موتور اسکالر، یک بلوک GPSIMD، و 32 مگابایت SRAM محلی که به جای کنترل توسط کش، به طور صریح توسط کامپایلر مدیریت میشود. از دیدگاه توسعه نرمافزار، این هسته بر اساس یک مدل جریان داده تعریفشده توسط نرمافزار ساخته شده است که در آن دادهها توسط موتورهای DMA به SRAM منتقل میشوند، توسط واحدهای اجرایی پردازش میشوند، و سپس به عنوان انباشت نزدیک به حافظه بازنویسی میشوند که DMA را قادر میسازد عملیات خواندن-افزودن-نوشتن را در یک تراکنش واحد انجام دهد. SRAM در بین هستهها منسجم نیست و برای کاشیکاری، مرحلهبندی و انباشت به جای کشینگ عمومی استفاده میشود.
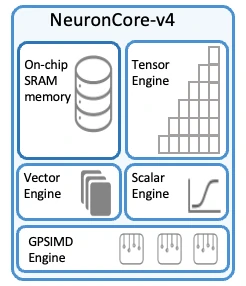
- موتور تنسور یک پردازنده ماتریسی به سبک سیستولیک برای عملیات GEMM، کانولوشن، ترانهاده و ضرب نقطهای است و از ورودیهای MXFP4، MXFP8، FP16، BF16، TF32 و FP32 با خروجیهای BF16 یا FP32 پشتیبانی میکند. در هر هسته، 315 ترافلاپس در MXFP8/MXFP4، 79 ترافلاپس در BF16/FP16/TF32 و 20 ترافلاپس در FP32 ارائه میدهد و شتابدهی پراکندگی ساختاریافته را با استفاده از الگوهای M:N (مانند 4:16، 4:12، 4:8، 2:8، 2:4، 1:4 و 1:2) پیادهسازی میکند که امکان دستیابی به همان اوج 315 ترافلاپس را در بارهای کاری پراکنده پشتیبانیشده فراهم میآورد.
- موتور برداری برای تبدیلهای برداری حدود 1.2 ترافلاپس FP32، تبدیل سختافزاری به فرمتهای MXFP و یک واحد توان سریع با چهار برابر توان عملیاتی مسیر توان اسکالر برای بارهای کاری توجه (attention workloads) را فراهم میکند. این واحد از انواع دادههای مختلفی از جمله FP8، FP16، BF16، TF32، FP32، INT8، INT16 و INT32 پشتیبانی میکند.
- موتور اسکالر نیز حدود 1.2 ترافلاپس FP32 را برای منطق کنترل و عملیات کوچک در انواع دادههای FP8 تا FP32 و اعداد صحیح فراهم میکند.
شاید جالبترین جزء NeuronCore-v4، بلوک GPSIMD باشد که هشت پردازنده برداری 512 بیتی کاملاً قابل برنامهریزی را یکپارچه میکند که میتوانند کدهای عمومی نوشته شده در C/C++ را در حین دسترسی به SRAM محلی اجرا کنند. GPSIMD در NeuronCore ادغام شده است زیرا همه چیز در مدلهای واقعی هوش مصنوعی به طور تمیز به یک موتور تنسور نگاشت نمیشود. بارهای کاری مدرن هوش مصنوعی شامل کدهای زیادی برای چیدمانهای غیرمعمول داده، منطق پسپردازش، نمایهسازی و محاسبات خاص مدل هستند. بیان این موارد به عنوان عملیات ماتریسی دشوار یا ناکارآمد است و اجرای آنها بر روی CPU میزبان باعث تأخیر و انتقال دادههای پرهزینه میشود. GPSIMD این مشکل را با ارائه واحدهای برداری قابل برنامهریزی عمومی واقعی در داخل هسته حل میکند، بنابراین چنین منطقی مستقیماً در کنار تنسورها با سرعت کامل و با استفاده از همان SRAM محلی اجرا میشود.

به طور خلاصه، NeuronCore-v4 به عنوان یک موتور جریان داده با اتصال محکم عمل میکند که در آن محاسبات تنسور، تبدیلهای برداری، کنترل اسکالر و کدهای سفارشی همگی یک حافظه موقت (scratchpad) محلی 32 مگابایتی را به اشتراک میگذارند و توسط کامپایلر Neuron به جای یک زمانبند warp که در سختافزار انویدیا استفاده میشود، هماهنگ میشوند.
از نظر عملکرد، Trainium3 در محاسبات FP8 (یا MXFP8) تقریباً دو برابر از نسل قبلی خود پیشی میگیرد و به 2.517 پتافلاپس در هر بسته میرسد (به وضوح جلوتر از H100/H200 انویدیا، اما عقبتر از Blackwell B200/B300) و پشتیبانی از MXFP4 را اضافه میکند. با این حال، عملکرد BF16، TF32 و FP32 Trainium3 با Trainium2 یکسان باقی میماند، که به وضوح نشان میدهد AWS برای آموزش و استنتاج در آینده روی MXFP8 شرطبندی میکند. به همین دلیل، قابلیتهای BF16 (که امروزه به طور گسترده برای آموزش استفاده میشود) و FP32 خود را توسعه نمیدهد، زیرا به نظر میرسد با عملکرد فعلی خود راحت است، با توجه به اینکه این فرمتها اکنون عمدتاً برای انباشت گرادیان، وزنهای اصلی، حالتهای بهینهساز، مقیاسبندی از دست دادن و برخی عملیات حساس به دقت استفاده میشوند.
یکی از قابلیتهای جالب Trainium3 که ارزش ذکر دارد، ویژگی پیکربندی منطقی NeuronCore (LNC) است که به کامپایلر Neuron اجازه میدهد چهار هسته فیزیکی را در یک هسته منطقی گستردهتر و به طور خودکار همگامسازی شده با محاسبات، SRAM و HBM ترکیب کند، که میتواند برای لایههای بسیار گسترده یا طولهای توالی بزرگ که در مدلهای هوش مصنوعی بسیار بزرگ رایج هستند، مفید باشد.
Trn3 UltraServers شرکت AWS: تقریباً شکست دادن GB300 NVL72 انویدیا
بخش عمدهای از موفقیت انویدیا در فصول اخیر ناشی از راهحلهای NVL72 در مقیاس رک آن بود که شامل 72 پردازنده گرافیکی Blackwell میشد. این راهحل از یک اندازه جهانی مقیاسپذیر عظیم و یک توپولوژی همه به همه پشتیبانی میکند که به ویژه برای Mixture-of-Experts (MoE) و استنتاج خودرگرسیو مهم است. این به انویدیا مزیت بزرگی نسبت به AMD و توسعهدهندگان شتابدهندههای سفارشی مانند AWS میدهد. برای فعال کردن این قابلیت، انویدیا مجبور شد سوئیچهای NVLink، کارتهای شبکه پیچیده و DPUها را توسعه دهد، که یک تلاش عظیم در زمینه سیلیکون بود. با این حال، به نظر میرسد Trn3 UltraServers شرکت AWS، GB300 NVL72 انویدیا را به چالش خواهد کشید.
Trn3 UltraServers، که توسط شتابدهندههای هوش مصنوعی Trainium3 تغذیه میشوند، در دو اندازه ارائه خواهند شد: یک پیکربندی شامل 64 شتابدهنده و احتمالاً یک CPU Intel Xeon است، در حالی که نسخه بزرگتر 144 شتابدهنده و یک Graviton مبتنی بر Arm را در یک راهحل مقیاس رک واحد گرد هم میآورد. در سیستم بزرگتر، 144 شتابدهنده Trainium3 در 36 سرور فیزیکی با یک CPU Graviton و چهار تراشه Trainium3 در هر ماشین توزیع شدهاند. از بسیاری جهات، چنین ترتیبی شبیه رویکرد NVL72 انویدیا است که از CPU، GPU و سیلیکون اتصال انویدیا استفاده میکند و جهتگیری AWS را در ساخت پلتفرمهای هوش مصنوعی یکپارچه عمودی برجسته میکند.

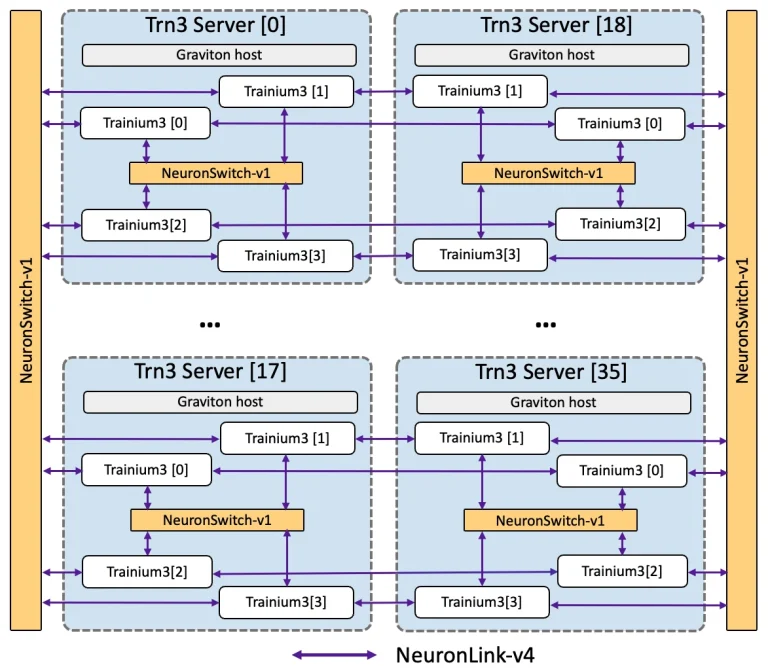
در داخل یک سرور، شتابدهندههای Trainium3 از طریق یک لایه اول NeuronSwitch-v1 با استفاده از NeuronLink-v4 (با سرعت 2 گیگابایت بر ثانیه در هر دستگاه، اگرچه مشخص نیست که آیا منظور پهنای باند یکطرفه است یا پهنای باند دوطرفه تجمیعشده) به هم متصل میشوند و ارتباط بین سرورهای مختلف از طریق دو لایه پارچه NeuronSwitch-v1 اضافی، که باز هم از طریق NeuronLink-v4 منتقل میشوند، مسیریابی میشود. متاسفانه، AWS پهنای باند تجمیعشده NeuronSwitch-v1 را در سراسر دامنه منتشر نمیکند.
از نظر عملکرد، پیکربندی بزرگتر با 144 Trainium3، عملکرد 362.5 پتافلاپس MXFP8/MXFP4 (متراکم) را ارائه میدهد که (همتراز با GB300 NVL72)، 96.624 پتافلاپس توان عملیاتی BF16/FP16/TF32 و 26.352 پتافلاپس در FP32 را به همراه دارد. این سیستم همچنین به 21 ترابایت حافظه HBM3E مجهز است که دارای پهنای باند حافظه تجمیعشده 705.6 ترابایت بر ثانیه است و GB300 NVL72 انویدیا را در این معیار پشت سر میگذارد.
به طور کلی، Trn3 Gen2 UltraServer از نظر عملکرد FP8 در برابر GB300 NVL72 انویدیا بسیار رقابتی به نظر میرسد. FP8 در حال محبوبتر شدن برای آموزش است، بنابراین شرطبندی روی این فرمت بسیار منطقی است. البته، انویدیا یک برگ برنده در آستین خود به شکل NVFP4 دارد که هم برای استنتاج و هم برای آموزش موقعیتیابی شده است، و با این فرمت، ماشینهای مبتنی بر Blackwell این شرکت شکستناپذیر هستند. همین امر در مورد BF16 نیز صدق میکند که در مقایسه با Trainium2 سریعتر شده است، اما نه به اندازهای که Blackwell انویدیا را شکست دهد.
در مجموع، در حالی که AWS Trn3 Gen2 UltraServer با 144 شتابدهنده Trainium3 در مقایسه با ماشینهای NVL72 مبتنی بر Blackwell انویدیا در زمینه FP8 کاملاً رقابتی به نظر میرسد، راهحل انویدیا به طور کلی جهانیتر است.
AWS Neuron در مسیر CUDA
علاوه بر عرضه سختافزار جدید هوش مصنوعی، AWS در کنفرانس سالانه re:Invent این هفته، گسترش وسیعی از پشته نرمافزاری AWS Neuron خود را اعلام کرد. AWS این انتشار را به عنوان حرکتی به سمت باز بودن و دسترسی توسعهدهندگان معرفی میکند، بنابراین این بهروزرسانی وعده میدهد که پلتفرمهای Trainium را آسانتر قابل پذیرش کند، به فریمورکهای استاندارد یادگیری ماشین اجازه دهد مستقیماً روی سختافزار Trainium اجرا شوند، به کاربران کنترل عمیقتری بر عملکرد بدهد و حتی مسیرهای بهینهسازی سطح پایین را برای متخصصان آشکار سازد.
یک افزودنی مهم، ادغام بومی PyTorch از طریق یک بکاند متنباز به نام TorchNeuron است. با استفاده از مکانیسم PrivateUse1 پایتورچ، Trainium اکنون به عنوان یک نوع دستگاه بومی ظاهر میشود که کدهای موجود پایتورچ را قادر میسازد بدون تغییر اجرا شوند. TorchNeuron همچنین از اجرای مشتاقانه تعاملی (interactive eager execution)، torch.compile و ویژگیهای توزیعشده مانند FSDP و DTensor پشتیبانی میکند و با اکوسیستمهای محبوبی از جمله TorchTitan و Hugging Face Transformers کار میکند. دسترسی به این ویژگی در حال حاضر به عنوان بخشی از برنامه پیشنمایش خصوصی، به کاربران منتخب محدود شده است.
AWS همچنین یک رابط هسته Neuron (NKI) بهروز شده را معرفی کرد که به توسعهدهندگان کنترل مستقیمی بر رفتار سختافزار، از جمله برنامهنویسی در سطح دستورالعمل، مدیریت صریح حافظه و زمانبندی دقیق میدهد و مجموعه دستورالعملهای Trainium را برای توسعهدهندگان هسته آشکار میسازد. علاوه بر این، این شرکت کامپایلر NKI را به صورت متنباز تحت مجوز Apache 2.0 منتشر کرده است. رابط برنامهنویسی به صورت عمومی در دسترس است، در حالی که خود کامپایلر در پیشنمایش محدود باقی میماند.
AWS همچنین Neuron Explorer خود را منتشر کرد، یک ابزار اشکالزدایی و تنظیم که به توسعهدهندگان نرمافزار و مهندسان عملکرد اجازه میدهد نحوه اجرای مدلهای خود را بر روی Trainium بهبود بخشند. این کار با ردیابی اجرا از فراخوانیهای فریمورک سطح بالا، تا دستورالعملهای شتابدهنده فردی، همراه با ارائه پروفایلسازی لایهای، دید در سطح منبع، ادغام با محیطهای توسعه و پیشنهادات مبتنی بر هوش مصنوعی برای تنظیم عملکرد انجام میشود.
در نهایت، AWS سیستم تخصیص منابع پویا Neuron (DRA) خود را معرفی کرد تا Trainium را مستقیماً در Kubernetes ادغام کند، بدون نیاز به زمانبندهای سفارشی. Neuron DRA بر زمانبند بومی Kubernetes تکیه میکند و آگاهی از توپولوژی سختافزار را اضافه میکند تا UltraServers کامل به عنوان یک منبع واحد تخصیص داده شوند و سپس سختافزار به طور انعطافپذیر برای هر بار کاری اختصاص یابد. Neuron DRA از Amazon EKS، SageMaker HyperPod و استقرار UltraServer پشتیبانی میکند و به عنوان نرمافزار متنباز با تصاویر کانتینر منتشر شده در رجیستری عمومی AWS ECR ارائه میشود.
هم Neuron Explorer و هم Neuron DRA برای سادهسازی مدیریت کلاستر و ارائه کنترل دقیق به کاربران بر نحوه تخصیص و استفاده از منابع Trainium طراحی شدهاند. به طور خلاصه، AWS در تلاش است تا پلتفرمهای مبتنی بر Trainium خود را بسیار فراگیرتر از آنچه امروز هستند، کند تا آنها را در برابر پیشنهادات مبتنی بر CUDA انویدیا رقابتیتر سازد.
به طور خلاصه
این هفته، آمازون وب سرویسز (AWS) شتابدهنده هوش مصنوعی Trainium نسل سوم خود را برای آموزش و استنتاج هوش مصنوعی، و همچنین راهحلهای مقیاس رک Trn3 UltraServers همراه آن را منتشر کرد. برای اولین بار، ماشینهای مقیاس رک Trn3 Gen2 UltraServers تنها بر سختافزار داخلی AWS، از جمله CPU، شتابدهندههای هوش مصنوعی، سختافزار سوئیچینگ و شبکههای اتصال تکیه خواهند کرد، که نشان میدهد این شرکت استراتژی یکپارچهسازی عمودی سختافزاری انویدیا را پذیرفته است.

AWS ادعا میکند که پردازنده Trainium3 آن تقریباً 2 برابر عملکرد بالاتر و 4 برابر بهرهوری انرژی بهتری نسبت به Trainium2 ارائه میدهد، زیرا هر شتابدهنده تا 2.517 پتافلاپس (MXFP8) ارائه میکند — که H100 انویدیا را شکست میدهد، اما از B200 عقبتر است — و با 144 گیگابایت HBM3E با پهنای باند 4.9 ترابایت بر ثانیه همراه است. در همین حال، Trn3 Gen2 UltraServers تا 144 شتابدهنده برای حدود 0.36 اگزافلاپس عملکرد FP8 مقیاسپذیر است که آن را همتراز با راهحل مقیاس رک GB300 NVL72 انویدیا قرار میدهد. با این وجود، سختافزار انویدیا همچنان جهانیتر از AWS به نظر میرسد.
برای رقابت با انویدیا، آمازون همچنین بهروزرسانیهای عمدهای را برای پشته نرمافزاری Neuron خود اعلام کرد تا پلتفرمهای مبتنی بر Trainium را آسانتر قابل استفاده کند، به فریمورکهای استاندارد یادگیری ماشین اجازه دهد به صورت بومی روی سختافزار اجرا شوند، به توسعهدهندگان کنترل بیشتری بر عملکرد بدهد و دسترسی به تنظیمات سطح پایین را برای متخصصان باز کند.
- کولبات
- آذر 14, 1404
- 112 بازدید






