
انویدیا جزئیات کارایی فرمت NVFP4 را برای آموزش مدلهای زبان بزرگ (LLM) تشریح میکند
هنگامی که انویدیا در اوایل سال جاری شروع به افشای جزئیات در مورد فرمت ممیز شناور 4 بیتی جدید خود — NVFP4 — کرد، اعلام داشت که اگرچه این فرمت عمدتاً برای استنتاج (inference) طراحی شده است، اما میتواند برای آموزش هوش مصنوعی نیز بدون افت قابل توجهی در دقت استفاده شود. اخیراً، این شرکت مقالهای منتشر کرد که در آن توضیح میدهد چگونه توانسته است یک مدل 12 میلیارد پارامتری را بر روی یک مجموعه داده 10 تریلیون توکنی با استفاده از فرمت NVFP4، همراه با چندین تکنیک پشتیبانی، آموزش دهد و به نتایجی دست یابد که به دقت با نتایج پایه FP8 مطابقت دارد.
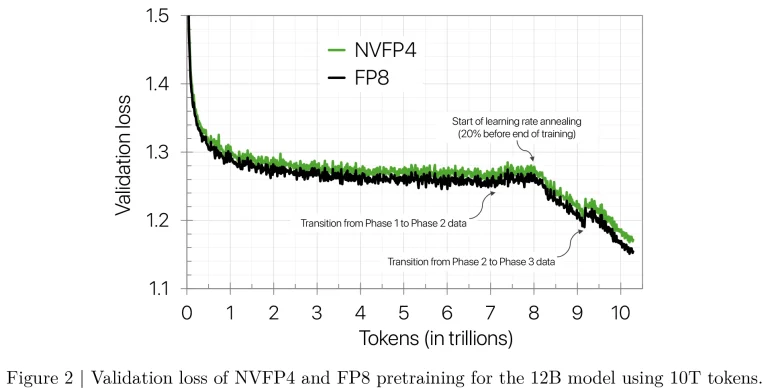
دستاورد انویدیا اولین نمونه شناخته شده از آموزش پایدار و در مقیاس بزرگ با دقت FP4 را نشان میدهد و ثابت میکند که NVFP4 میتواند به طور قابل توجهی مصرف حافظه و هزینه محاسباتی را بدون کاهش کیفیت مدل کاهش دهد.
بلکول و NVFP4: ترکیبی ایدهآل
NVFP4 انویدیا یک فرمت ممیز شناور 4 بیتی است که به طور خاص برای معماری پردازنده گرافیکی بلکول (Blackwell) توسعه یافته و هدف آن بهبود کارایی هر دو وظیفه آموزش و استنتاج است. این فرمت نمایش دادههای بسیار فشرده را با یک استراتژی مقیاسبندی چند سطحی ترکیب میکند و دقتی نزدیک به BF16 را در عین کاهش قابل توجه الزامات عملکرد و حافظه به دست میآورد.
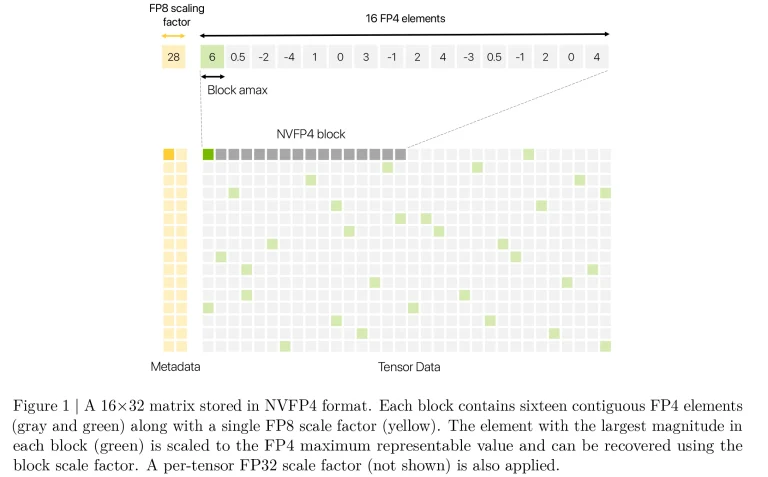
از نظر ساختاری، NVFP4 به همان طرح E2M1 مورد استفاده در فرمتهای استاندارد FP4 پایبند است — شامل 1 بیت علامت، 2 بیت توان و 1 بیت مانتیس — که به آن امکان میدهد مقادیر را تقریباً بین 6- و 6+ کدگذاری کند. برای غلبه بر محدوده دینامیکی ذاتاً محدود فرمتهای 4 بیتی، انویدیا یک مکانیزم مقیاسبندی سلسلهمراتبی را معرفی میکند: هر بلوک 16 عنصری از مقادیر FP4 یک عامل مقیاس اختصاصی دریافت میکند که در FP8 با استفاده از طرح E4M3 ذخیره میشود، و به موازات آن، یک عامل مقیاس FP32 به صورت سراسری در کل تانسور اعمال میشود. انویدیا ادعا میکند که این سیستم دو لایه، نویز عددی را پایین نگه میدارد بدون اینکه کارایی عملکردی که یک فرمت 4 بیتی ارائه میدهد را از دست بدهد.
جدیدترین پردازندههای گرافیکی بلکول انویدیا دارای هستههای تنسور (tensor cores) هستند که قادر به انجام ضرب ماتریسی عمومی (GEMM) در فرمتهای باریک مانند MXFP8، MXFP6، MXFP4 و NVFP4 میباشند. هستههای تنسور بلکول GEMMها را با اعمال یک عامل مقیاس به هر بلوک از مقادیر ورودی، انجام محاسبات ضرب نقطهای با دقت بالا، و سپس جمعآوری نتایج با دقت سطح FP32، دقیقاً به همان روشی که NVFP4 برای استفاده در نظر گرفته شده است، پردازش میکنند.
این هستهها همچنین از روشهای گرد کردن داخلی، از جمله گرد کردن به نزدیکترین عدد زوج (round-to-nearest-even) و گرد کردن تصادفی (stochastic rounding) پشتیبانی میکنند که برای اطمینان از آموزش پایدار هنگام استفاده از فرمتهای با دقت پایین مانند FP4 مهم هستند. انویدیا میگوید که عملیات NVFP4 در GB200 تا 4 برابر و در GB300 تا 6 برابر افزایش سرعت نسبت به BF16 را به دست میآورد. علاوه بر این، مصرف حافظه تقریباً نصف FP8 کاهش مییابد.
اما آیا میتوان از آن برای آموزش استفاده کرد؟
تنظیم مدل و رویکرد آموزش
برای ارزیابی کارایی NVFP4، انویدیا یک مدل زبان بزرگ 12 میلیارد پارامتری را بر اساس معماری هیبریدی مامبا-ترنسفورمر (Mamba-Transformer) آموزش داد. این معماری مدل از خانواده Nemotron-H بود و شامل ترکیبی از بلوکهای Mamba-2، لایههای استاندارد پیشخور (feed-forward) و ماژولهای خودتوجهی (self-attention) میشد. آموزش از یک برنامه زمانبندی گرمکردن-پایدار-کاهش (warmup-stable-decay) پیروی کرد: نرخ یادگیری در 80 درصد اول اجرا ثابت ماند و به تدریج در 20 درصد پایانی کاهش یافت.
توجه داشته باشید که NVFP4 میتواند برای مدلهایی مانند LLaMA، GPT اوپنایآی و سایر LLMهای مبتنی بر ترنسفورمر اعمال شود؛ این فرمت قطعاً مختص معماری مامبا-ترنسفورمر مورد استفاده در این نمایش نیست. با این حال، تطبیق آن ممکن است نیاز به تنظیم تعداد لایههای BF16، اعتبارسنجی انتخابهای مقیاسبندی بلوک و انجام آموزش آگاه از کوانتیزاسیون (quantization-aware training) داشته باشد، اگر مدل در ابتدا برای فرمتهای با دقت پایین طراحی نشده باشد.
هر توالی آموزشی شامل 8192 توکن بود و اندازه دسته (batch size) روی 736 تنظیم شد. مجموعه داده مورد استفاده برای آموزش ترکیبی متنوع از انواع محتوا بود، از جمله متن عمومی اینترنت، کد برنامهنویسی، مسائل ریاضی، پیکرههای چندزبانه، مقالات دانشگاهی و نمونههای مصنوعی تنظیم شده با دستورالعمل. ترکیب در سه مرحله انجام شد تا از قرار گرفتن متعادل در معرض انواع دادهها در طول آموزش اطمینان حاصل شود.
دقت در مقایسه با FP8
در طول آموزش، مدل آموزشدیده با NVFP4 از نظر افت اعتبارسنجی (validation loss) بسیار نزدیک به پایه FP8 عمل کرد. به گفته انویدیا، برای بیشتر مدت اجرا، شکاف افت بین NVFP4 و FP8 زیر 1% باقی ماند و تنها کمی بالاتر از 1.5% در نزدیکی پایان، زمانی که نرخ یادگیری شروع به کاهش کرد، افزایش یافت. با این حال، این افزایش کوچک در افت به کاهش قابل اندازهگیری در دقت وظیفه منجر نشد.
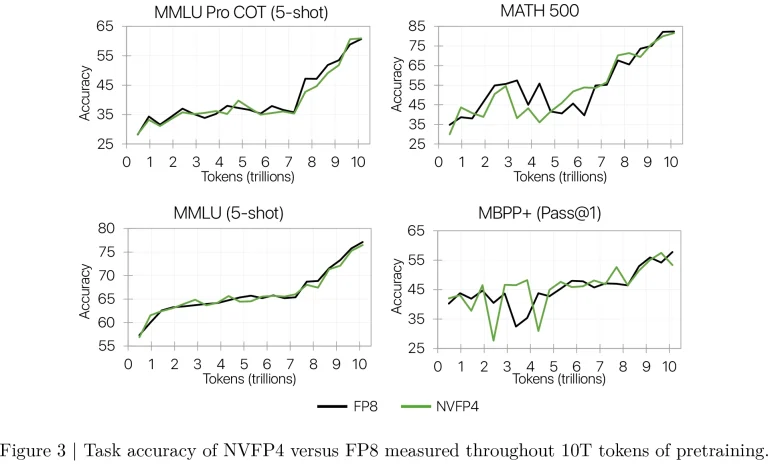
NVFP4 نتایج قابل مقایسهای با FP8 در طیف وسیعی از وظایف پاییندستی، از جمله استدلال عقل سلیم، ریاضیات، سوالات دانشمحور و معیارهای چندزبانه به دست آورد. به عنوان مثال، NVFP4 در معیار MMLU-Pro 5-shot به 62.58% رسید که تقریباً با نتیجه 62.62% FP8 مطابقت داشت. تنها افت دقت قابل توجه در وظایف مرتبط با کد مانند MBPP+ و HumanEval+ رخ داد، جایی که NVFP4 چند درصد عقبتر بود. با این حال، این ناسازگاری به تغییرپذیری طبیعی نقاط بازرسی (checkpoint variability) نسبت داده شد تا نقص سیستمی در فرمت.

تکنیکهایی برای آموزش پایدار 4 بیتی
آموزش مدلهای بزرگ با دقت FP4 نیازمند چندین تنظیم برای اطمینان از پایداری و دقت است. یکی از استراتژیهای کلیدی، نگه داشتن حدود 15% از لایههای خطی در BF16 است، عمدتاً در بلوکهای نهایی مدل. استفاده از NVFP4 در تمام لایهها منجر به واگرایی شد، اما انویدیا دریافت که حتی حفظ تنها چهار بلوک آخر در BF16 برای آموزش پایدار کافی است، که نشان میدهد ردپای BF16 میتواند بیشتر کاهش یابد.
برای حفظ سازگاری بین گذر رو به جلو و رو به عقب (که از وزنهای ترانهاده استفاده میکنند)، انویدیا از مقیاسبندی بلوکی 2 بعدی برای وزنها استفاده کرد: وزنها در بلوکهای 16×16 با یک عامل مقیاس مشترک که در هر دو جهت اعمال میشد، گروهبندی شدند. برای فعالسازیها و گرادیانها، از مقیاسبندی بلوکی دقیقتر 1×16 استفاده شد که دقت کوانتیزاسیون را بدون ایجاد ناپایداری بهبود بخشید.
برای مقابله با نقاط پرت (outliers) در گرادیانها، انویدیا تبدیلهای تصادفی هادامارد (Random Hadamard Transforms) را به ورودیهای گرادیان وزن (Wgrad) اعمال کرد تا مقادیر بزرگ بازتوزیع شده را به طور یکنواختتر تبدیل کرده و نمایش آنها را در FP4 آسانتر کند. با این حال، چنین تبدیلهایی به سایر انواع تنسور اعمال نشد و یک ماتریس 16×16 با یک بردار علامت تصادفی مشترک در تمام لایهها استفاده شد.
در نهایت، گرد کردن تصادفی شتابیافته سختافزاری برای کوانتیزاسیون گرادیان استفاده شد. این کار به جلوگیری از سوگیری گرد کردن (rounding bias) که میتواند در طول آموزش ایجاد شود، کمک کرد. همچنین، انویدیا آن را فقط به گرادیانها اعمال کرد، زیرا استفاده از آن بر روی فعالسازیهای رو به جلو، نویز را افزایش داده و کیفیت آموزش را کاهش میداد.
تغییر دقت در مراحل پایانی
در سناریوهایی که به حداقل رساندن افت نهایی (final loss) حیاتی است، انویدیا تغییر از NVFP4 به BF16 را در مراحل پایانی آموزش آزمایش کرد. تغییری که در 8.2 تریلیون توکن انجام شد، شکاف در افت نهایی را به طور قابل توجهی کاهش داد. تغییر تنها مسیر رو به جلو به BF16 تقریباً همان اثری را داشت که تغییر هر دو گذر رو به جلو و رو به عقب. در مقابل، تغییر در 10 تریلیون توکن — نزدیک به پایان آموزش — به دلیل نرخ یادگیری از قبل پایین، تأثیر حداقلی داشت. این نتایج نشان میدهد که استفاده محدود از دقت بالا در نزدیکی پایان آموزش میتواند دقت را بهبود بخشد در حالی که بیشتر مزایای کارایی FP4 را حفظ میکند.
NVFP4 در مقابل MXFP4
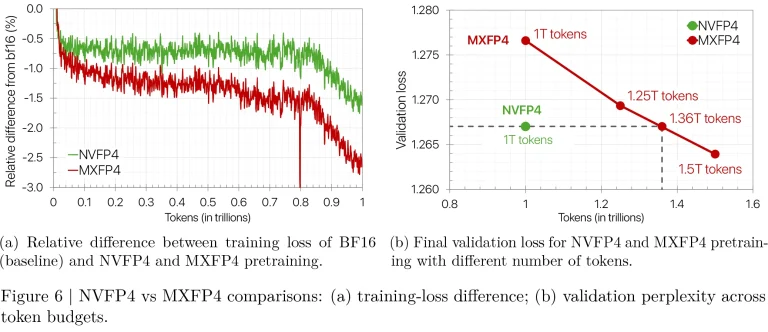
برای مقایسه NVFP4 با فرمت رایجتر MXFP4 که توسط پروژه Open Compute تعریف شده است (و توسط پردازندههای سری Ascend 950 آینده هواوی و بعد از آن پشتیبانی میشود)، انویدیا یک مدل 8 میلیارد پارامتری را با استفاده از هر دو فرمت بر روی یک مجموعه داده 1 تریلیون توکنی آموزش داد. NVFP4 افت نهایی تقریباً 1.5% بالاتر از مرجع BF16 را به دست آورد، در حالی که افت نهایی MXFP4 حدود 2.5% بالاتر بود. برای مطابقت با افت نهایی NVFP4، مدل MXFP4 به 1.36 تریلیون توکن، یا 36% داده بیشتر نیاز داشت.
آموزش هوش مصنوعی از NVFP4 بهرهمند میشود
فرمت NVFP4 انویدیا، طبق آزمایشهای خود شرکت، آموزش دقیق، پایدار و کارآمد مدلهای زبان بزرگ (LLM) در مقیاس وسیع را با استفاده از دقت 4 بیتی امکانپذیر میسازد. با ترکیب یک فرمت کوانتیزاسیون دقیقتر با تکنیکهایی مانند دقت ترکیبی (mixed precision)، مقیاسبندی ثابت، گرد کردن تصادفی و مدیریت نقاط پرت، این شرکت با موفقیت یک مدل 12 میلیارد پارامتری در کلاس پیشرو را بر روی مجموعه داده 10 تریلیون توکنی آموزش داد.
در مقایسه با فرمت MXFP4، NVFP4 در هر دو زمینه همگرایی و کارایی داده از آن پیشی میگیرد.
کار آینده انویدیا بر کاهش بیشتر تعداد لایههای با دقت بالا، گسترش NVFP4 به اجزای بیشتر مدل و ارزیابی اثربخشی آن در مدلهای بزرگتر و معماریهای جایگزین متمرکز خواهد بود.
- کولبات
- مهر 13, 1404
- 91 بازدید






