
ایلان ماسک میگوید xAI در پنج سال آینده ۵۰ میلیون پردازنده گرافیکی هوش مصنوعی «معادل H100» را هدف قرار داده است — ۲۳۰ هزار پردازنده گرافیکی، شامل ۳۰ هزار GB200، قبلاً برای آموزش Grok عملیاتی شدهاند.
شرکتهای پیشرو در زمینه هوش مصنوعی درباره تعداد پردازندههای گرافیکی (GPU) که استفاده میکنند یا قصد دارند در آینده استفاده کنند، لاف زدهاند. همین دیروز، OpenAI برنامههایی برای ساخت زیرساختی برای تامین انرژی دو میلیون پردازنده گرافیکی اعلام کرد، اما اکنون ایلان ماسک برنامههایی حتی عظیمتر را فاش کرده است: معادل ۵۰ میلیون پردازنده گرافیکی H100 که قرار است طی پنج سال آینده برای استفاده در هوش مصنوعی مستقر شوند. اما در حالی که تعداد معادلهای H100 بسیار زیاد به نظر میرسد، تعداد واقعی پردازندههای گرافیکی که مستقر خواهند شد ممکن است به آن اندازه زیاد نباشد. برخلاف قدرتی که مصرف خواهند کرد.
۵۰ اگزافلاپس برای آموزش هوش مصنوعی
ایلان ماسک در یک پست X نوشت: «هدف xAI، ۵۰ میلیون واحد معادل H100 برای محاسبات هوش مصنوعی (اما با بهرهوری انرژی بسیار بهتر) است که ظرف ۵ سال آنلاین شوند.»
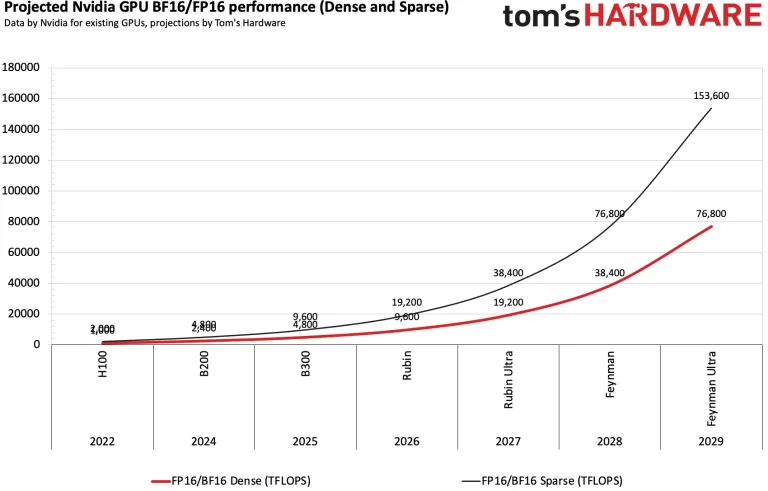
یک پردازنده گرافیکی Nvidia H100 میتواند حدود ۱۰۰۰ ترافلاپس FP16/BF16 برای آموزش هوش مصنوعی ارائه دهد (اینها در حال حاضر محبوبترین فرمتها برای آموزش هوش مصنوعی هستند)، بنابراین ۵۰ میلیون از این شتابدهندههای هوش مصنوعی باید تا سال ۲۰۳۰، ۵۰ اگزافلاپس FP16/BF16 برای آموزش هوش مصنوعی ارائه دهند. بر اساس روندهای فعلی بهبود عملکرد، این امر در پنج سال آینده بیش از حد قابل دستیابی است.
تنها ۶۵۰,۰۰۰ پردازنده گرافیکی Feynman Ultra
با فرض اینکه انویدیا (و دیگران) به مقیاسبندی عملکرد آموزش BF16/FP16 پردازندههای گرافیکی خود با سرعتی کمی کندتر از نسلهای Hopper و Blackwell ادامه دهند، ۵۰ اگزافلاپس BF16/FP16 با استفاده از ۱.۳ میلیون پردازنده گرافیکی در سال ۲۰۲۸ یا ۶۵۰,۰۰۰ پردازنده گرافیکی در سال ۲۰۲۹، بر اساس حدسهای گمانهزنی ما، قابل دستیابی خواهد بود.
اگر xAI پول کافی برای صرف سختافزار انویدیا داشته باشد، حتی ممکن است هدف رسیدن به ۵۰ اگزافلاپس برای آموزش هوش مصنوعی زودتر محقق شود.
xAI ایلان ماسک در حال حاضر یکی از سریعترین شرکتها در استقرار جدیدترین شتابدهندههای پردازنده گرافیکی هوش مصنوعی برای افزایش قابلیت آموزش خود است. این شرکت در حال حاضر ابرخوشه Colossus 1 خود را که از ۲۰۰,۰۰۰ شتابدهنده H100 و H200 مبتنی بر معماری Hopper استفاده میکند، و همچنین ۳۰,۰۰۰ واحد GB200 مبتنی بر معماری Blackwell را به کار میگیرد. علاوه بر این، این شرکت قصد دارد خوشه Colossus 2 خود را متشکل از ۵۵۰,۰۰۰ گره GB200 و GB300 (هر یک از این گرهها دارای دو پردازنده گرافیکی هستند، بنابراین خوشه بیش از یک میلیون پردازنده گرافیکی خواهد داشت) بسازد که اولین گرهها قرار است در هفتههای آینده آنلاین شوند، طبق گفته ماسک.
افزایش مداوم عملکرد
انویدیا (و سایر شرکتها) اخیراً به یک چرخه سالانه انتشار شتابدهندههای جدید هوش مصنوعی روی آوردهاند و برنامه انویدیا اکنون شبیه مدل Tick-Tock اینتل در گذشته است، اگرچه در این مورد ما در مورد یک رویکرد معماری -> بهینهسازی با استفاده از یک گره تولید واحد (مانند Blackwell -> Blackwell Ultra, Rubin -> Rubin Ultra) صحبت میکنیم تا تغییر به یک فناوری فرآیند جدید برای یک معماری شناخته شده.
چنین رویکردی افزایش قابل توجهی در عملکرد هر سال را تضمین میکند، که به نوبه خود افزایشهای چشمگیر عملکرد بلندمدت را تضمین میکند. به عنوان مثال، انویدیا ادعا میکند که Blackwell B200 آن ۲۰,۰۰۰ برابر عملکرد استنتاجی بالاتری نسبت به Pascal P100 سال ۲۰۱۶ ارائه میدهد، که حدود ۲۰,۰۰۰ ترافلاپس FP4 در مقابل ۱۹ ترافلاپس FP16 P100 را ارائه میدهد. اگرچه مقایسه مستقیمی نیست، اما این معیار برای وظایف استنتاجی مرتبط است. Blackwell همچنین ۴۲,۵۰۰ برابر از Pascal از نظر بهرهوری انرژی کارآمدتر است که با ژول در هر توکن تولید شده اندازهگیری میشود.
در واقع، انویدیا و دیگران با پیشرفتهای عملکردی کند نمیشوند. معماری Blackwell Ultra (سری B300) عملکرد FP4 را ۵۰٪ بالاتر (۱۵ فلوپس) در مقایسه با پردازندههای گرافیکی اصلی Blackwell (۱۰ فلوپس) برای استنتاج هوش مصنوعی، و همچنین دو برابر عملکرد بالاتر برای فرمتهای BF16 و TF32 برای آموزش هوش مصنوعی ارائه میدهد، اما به قیمت عملکرد پایینتر INT8، FP32 و FP64. برای مرجع، BF16 و FP16 فرمتهای معمولی هستند که برای آموزش هوش مصنوعی استفاده میشوند (اگرچه به نظر میرسد FP8 نیز در حال ارزیابی است)، بنابراین منطقی است که انتظار داشته باشیم انویدیا عملکرد را در این فرمتها با پردازندههای گرافیکی نسل بعدی Rubin، Rubin Ultra، Feynman و Feynman Ultra خود افزایش دهد.
بسته به نحوه شمارش ما، انویدیا عملکرد FP16/BF16 را با H100 (در مقایسه با A100) ۳.۲ برابر، سپس با B200 (در مقایسه با H100) ۲.۴ برابر، و سپس با B300 (در مقایسه با B200) ۲.۲ برابر افزایش داد. عملکرد واقعی آموزش البته نه تنها به عملکرد ریاضی خالص پردازندههای گرافیکی جدید، بلکه به پهنای باند حافظه، اندازه مدل، موازیسازی (بهینهسازیهای نرمافزاری و عملکرد اتصال داخلی) و استفاده از FP32 برای انباشتگیها نیز بستگی دارد. با این حال، میتوان با اطمینان گفت که انویدیا میتواند عملکرد آموزش (با فرمتهای FP16/BF16) پردازندههای گرافیکی خود را با هر نسل جدید دو برابر کند.
با فرض اینکه انویدیا بتواند افزایشهای عملکردی ذکر شده را با چهار نسل بعدی شتابدهندههای هوش مصنوعی خود بر اساس معماریهای Rubin و Feynman به دست آورد، به راحتی میتوان محاسبه کرد که حدود ۶۵۰,۰۰۰ پردازنده گرافیکی Feynman Ultra برای رسیدن به حدود ۵۰ اگزافلاپس BF16/FP16 در سال ۲۰۲۹ مورد نیاز خواهد بود.
مصرف برق عظیم
اما در حالی که xAI ایلان ماسک و احتمالاً سایر رهبران هوش مصنوعی احتمالاً ۵۰ اگزافلاپس BF16/FP16 خود را برای آموزش هوش مصنوعی طی چهار یا پنج سال آینده به دست خواهند آورد، سوال بزرگ این است که چنین ابرخوشهای چقدر برق مصرف خواهد کرد؟ و چند نیروگاه هستهای برای تغذیه آن مورد نیاز خواهد بود؟
یک شتابدهنده هوش مصنوعی H100، ۷۰۰ وات مصرف میکند، بنابراین ۵۰ میلیون از این پردازندهها ۳۵ گیگاوات (GW) مصرف خواهند کرد، که برابر با توان تولیدی معمول ۳۵ نیروگاه هستهای است، و تامین انرژی چنین مرکز داده عظیمی را در حال حاضر غیرواقعی میکند. حتی یک خوشه Rubin Ultra حدود ۹.۳۷ گیگاوات نیاز خواهد داشت، که قابل مقایسه با مصرف برق گویان فرانسه است. با فرض اینکه معماری Feynman عملکرد به ازای هر وات را برای BF16/FP16 در مقایسه با معماری Rubin دو برابر کند (به خاطر داشته باشید که ما در حال گمانهزنی هستیم)، یک خوشه ۵۰ اگزافلاپس همچنان به ۴.۶۸۵ گیگاوات نیاز خواهد داشت، که بسیار فراتر از ۱.۴ گیگاوات – ۱.۹۶ گیگاوات مورد نیاز برای مرکز داده Colossus 2 xAI با حدود یک میلیون شتابدهنده هوش مصنوعی است.
آیا xAI ایلان ماسک میتواند ۴.۶۸۵ گیگاوات برق برای تغذیه یک مرکز داده ۵۰ اگزافلاپس در سالهای ۲۰۲۸ – ۲۰۳۰ به دست آورد؟ این چیزی است که به وضوح باید دید.
برای دریافت اخبار، تحلیلها و بررسیهای بهروز ما، در Google News دنبال کنید. حتماً روی دکمه دنبال کردن کلیک کنید.
- کولبات
- مرداد 3, 1404
- 30 بازدید






