
دو سیستم Nvidia DGX Spark با مک استودیو M3 Ultra ترکیب شدند تا یک سیستم LLM فوقالعاده سریع ایجاد کنند
پروژه اصلی EXO Labs، فریمورک متنباز EXO است که برای اجرای کارآمد مدلهای زبان بزرگ (LLM) در تنظیمات سختافزاری ترکیبی طراحی شده است. EXO به جای اینکه استنتاج را وظیفهای محدود به یک GPU یا شتابدهنده بداند، به طور خودکار بار کاری را بین هر دستگاهی که در اختیار دارید توزیع میکند – یک خوشه از دسکتاپها، لپتاپها، ایستگاههای کاری، سرورها، تبلتها یا حتی گوشیهای هوشمند را به یک شبکه هوش مصنوعی تعاونی تبدیل میکند. جدیدترین دمو EXO، دو سیستم NVIDIA DGX Spark را با مک استودیو مجهز به M3 Ultra اپل ترکیب میکند تا از نقاط قوت متفاوت هر دستگاه بهره ببرد: Spark قدرت محاسباتی خام بیشتری دارد، در حالی که مک استودیو میتواند دادهها را بسیار سریعتر جابجا کند. EXO 1.0، که در حال حاضر در دسترسی اولیه است، این دو را در یک خط لوله استنتاج واحد ادغام میکند و ظاهراً به طرز شگفتانگیزی خوب کار میکند.

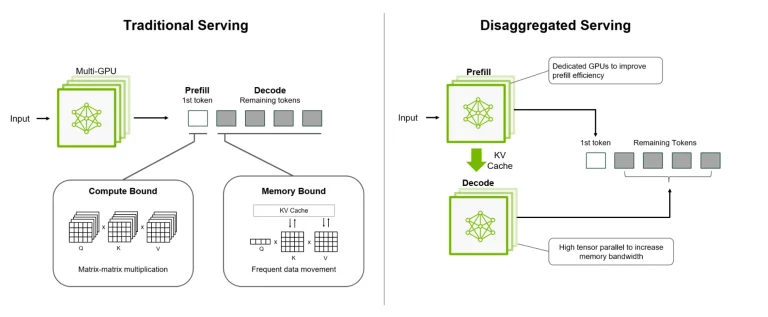
برای درک چگونگی آن، باید بدانید که استنتاج LLM دو فاز متمایز دارد: اول، مرحله پیشپر کردن (prefill)، زمانی که مدل، درخواست کاربر را میخواند و پردازش میکند. این بخش وابسته به محاسبات است، به این معنی که از GPUهای قدرتمند مانند بخش Blackwell در DGX Spark بهره میبرد. فاز رمزگشایی (decode) به دنبال آن میآید و توکنها را یکی یکی تولید میکند. این مرحله به شدت وابسته به پهنای باند است، که باس حافظه فوقالعاده عریض M3 Ultra را ایدهآل میکند. ترفند EXO این است که این فازها را بین ماشینها تقسیم کند و دادههای داخلی مدل (که کش KV نامیده میشود) را لایه به لایه استریم کند تا دو سیستم بتوانند به طور همزمان کار کنند به جای اینکه منتظر یکدیگر بمانند.
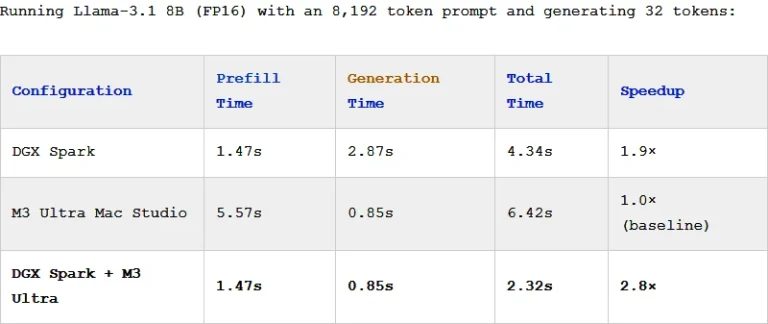
در بنچمارک EXO با مدل Llama-3.1 8B متا، تنظیمات هیبریدی تقریباً سه برابر سرعت بیشتری نسبت به مک استودیو به تنهایی به دست آورد – سرعت پیشپر کردن DGX Spark را با زمان تولید سریع M3 Ultra مطابقت داد. نتیجه یک افزایش کلی 2.8 برابری است، و این با یک درخواست 8K توکنی در یک مدل 8B نسبتاً متوسط بود. درخواستهای طولانیتر یا مدلهای بزرگتر باید افزایشهای بیشتری را مشاهده کنند.
این نوع “استنتاج غیرمتمرکز” دقیقاً یک نوآوری نیست، اما همچنان بسیار هوشمندانه است. این به آیندهای اشاره دارد که در آن عملکرد هوش مصنوعی نه با خرید یک شتابدهنده عظیم، بلکه با هماهنگی هوشمندانهتر سختافزارهایی که از قبل دارید، مقیاسپذیر میشود. به نظر میرسد NVIDIA نیز موافق است: پلتفرم آتی Rubin CPX آن از پردازندههای Rubin CPX با چگالی محاسباتی بالا برای مرحله پیشپر کردن (ساخت زمینه) استفاده خواهد کرد، در حالی که تراشههای استاندارد Rubin با پهنای باند عظیم حافظه HBM3e مرحله رمزگشایی را مدیریت میکنند – همان اصلی که EXO در حال حاضر روی سختافزارهای آماده به کار نشان میدهد.
نسخه دسترسی اولیه EXO هنوز در مراحل آزمایشی است. نسخه متنباز فعلی (0.0.15-alpha) به مارس 2025 بازمیگردد، و ساخت کامل 1.0 – با زمانبندی خودکار، استریمینگ KV و بهینهسازیهای ناهمگن – هنوز عمومی نشده است. این نرمافزار آماده استفاده برای مصرفکنندگان نیست، حداقل هنوز نه؛ در حال حاضر، این یک ابزار تحقیقاتی است که ثابت میکند استنتاج غیرمتمرکز میتواند دستاوردهای واقعی به ارمغان بیاورد.
با این حال، این یک اثبات مفهوم هیجانانگیز است. EXO با استفاده هوشمندانه از سختافزارهای ترکیبی نشان میدهد که هوش مصنوعی با کارایی بالا لزوماً نباید در انحصار مراکز داده باشد. این کافی است تا شما را به فکر پتانسیل دستگاههای موجود در دفترتان بیندازد.

- کولبات
- مهر 24, 1404
- 248 بازدید






