
ماژول فلش جدید 5 ترابایتی و 64 گیگابایت بر ثانیه کیوکسیا، NAND را به سمت باس حافظه برای پردازندههای گرافیکی هوش مصنوعی سوق میدهد
کیوکسیا نمونه اولیه ماژول حافظه فلش با پهنای باند بالا 5 ترابایتی را با پهنای باند 64 گیگابایت بر ثانیه توسعه داده است. این در اصل حافظه مبتنی بر NAND برای پردازندههای گرافیکی (GPU) است. در مقایسه با HBM، فلش با پهنای باند بالا (HBF) این مفهوم را با فلش NAND تطبیق میدهد و 8 تا 16 برابر ظرفیت HBM مبتنی بر DRAM را ارائه میکند. با ترکیب سرعت با ذخیرهسازی پایدار، HBF امکان دسترسی کارآمد به مجموعهدادههای بزرگ هوش مصنوعی را با مصرف انرژی کمتر فراهم میآورد. یکی از این ماژولهای HBF، که کیوکسیا آن را به 64 گیگابایت بر ثانیه رسانده است، همین قابلیت را ممکن میسازد.
وقتی عبارت «ذخیرهسازی فلش» را میشنوید، معمولاً ابتدا به ظرفیت و سپس به سرعت فکر میکنید. حتی سریعترین SSDهای PCIe 5.0 امروزی — درایوهای کلاس 14 گیگابایت بر ثانیه مانند 9100 Pro سامسونگ — در برابر تقاضای پهنای باند پردازندههای گرافیکی و مرکزی مدرن ناچیز به نظر میرسند. نمونه اولیه جدید کیوکسیا این انتظار را بر هم میزند: یک ماژول فلش واحد که 5 ترابایت ظرفیت و 64 گیگابایت بر ثانیه پهنای باند پایدار را از طریق PCIe 6.0 ارائه میدهد. برای درک بهتر، این سرعت بیش از 4 برابر سریعتر از سریعترین درایوهای PCIe 5.0 موجود در بازار است و به توان عملیاتی هر پشته HBM2E نزدیک میشود.
نکته کلیدی در نحوه مقیاسپذیری سیستم است؛ به جای یک کنترلکننده مرکزی که سعی در مدیریت کل بانک NAND دارد — که با افزودن دایها و کانالهای بیشتر به سرعت به یک گلوگاه تبدیل میشود — کیوکسیا به هر ماژول کنترلکننده خاص خود را میدهد. این کنترلکننده درست در کنار NAND خود قرار میگیرد و به صورت زنجیرهای به سایرین متصل میشود. این کار تداخل را کاهش میدهد و پیچیدگی باسهای موازی گسترده را که با افزایش سرعت مدیریت آنها چالشبرانگیزتر میشود، از بین میبرد. در عوض، دادهها به صورت سریالی منتقل میشوند و هر لینک با استفاده از سیگنالینگ PAM4، سرعت 128 گیگابیت بر ثانیه را ارائه میدهد.



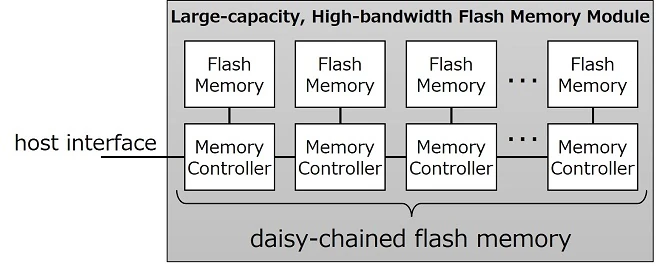
PAM4 (مدولاسیون دامنه پالس با چهار سطح) نرخ داده در هر نماد را در مقایسه با سیگنالینگ سنتی NRZ دو برابر میکند، اما همچنین نسبت به نویز و خطاهای بیتی حساستر است. برای حفظ یکپارچگی سیگنال، کیوکسیا به یکسانسازی، تصحیح خطا و پیشتاکید قویتر متکی است — مشابه آنچه خود PCIe 6.0 نیاز دارد.
این به توضیح حرکت به سمت PCIe 6.0 به عنوان رابط میزبان کمک میکند، زیرا 16 خط PCIe 6.0 میتوانند به طور نظری حدود 128 گیگابایت بر ثانیه دوطرفه را مدیریت کنند. هدف 64 گیگابایت بر ثانیه کیوکسیا کمی کمتر از نیمی از این حد است و فضای کافی برای تصحیح خطا و سربار بدون اشغال کامل باس باقی میگذارد.
همانطور که ممکن است انتظار داشته باشید، تأخیر اصلیترین نقطه ضعف است. حافظه HBM در حد صدها نانوثانیه کار میکند، تقریباً مانند یک افزونه برای رجیسترهای GPU. فلش NAND — حتی با کنترلکنندههای پیشرفته — همچنان در دهها میکروثانیه به دادهها دسترسی پیدا میکند که به مراتب کندتر است. کیوکسیا این مشکل را با پیشواکشی تهاجمی و کشسازی در سطح کنترلکننده جبران میکند، بنابراین بارهای کاری متوالی کمتر تحت تأثیر قرار میگیرند. این کار NAND را به سرعت DRAM نمیرساند، اما شکاف را به اندازهای کم میکند که برای مجموعهدادههای جریانی، نقاط بازرسی هوش مصنوعی یا تحلیلهای گراف بزرگ، پهنای باند مهمتر از تأخیر خام است.
توان مصرفی عامل حیاتی دیگری در اینجا است، زیرا کیوکسیا ادعا میکند که هر ماژول کمتر از 40 وات مصرف میکند، که در مقایسه با SSDهای Gen5 سنتی که میتوانند تا 15 وات برای حدود 14 گیگابایت بر ثانیه مصرف کنند، چشمگیر به نظر میرسد. بر اساس گیگابایت بر ثانیه در هر وات، این ماژول به طور چشمگیری کارآمدتر است. این موضوع اهمیت دارد زیرا در یک رک هایپراسکیل، چند صد درایو میتوانند به راحتی چندین کیلووات مصرف کنند. مراکز داده هوش مصنوعی — که به لطف خوشههای H100 در حال حاضر بودجههای توان آنها در حال افزایش است — به هر وات صرفهجویی شده در لایه ذخیرهسازی نیاز دارند.
این ماژولها همچنین گزینههای جدیدی برای طراحی سیستم باز میکنند. با کنترلکنندههای زنجیرهای، افزودن ماژولهای بیشتر پهنای باند اضافی مصرف نمیکند، بنابراین عملکرد به صورت خطی با ظرفیت مقیاسپذیر است. یک مجموعه کامل از 16 ماژول میتواند به 80 ترابایت فلش و بیش از 1 ترابایت بر ثانیه توان عملیاتی برسد — اعدادی که زمانی محدود به سیستمهای فایل موازی یا حافظههای موقت DRAM بودند. این امکان را فراهم میکند که ذخیرهسازی به عنوان حافظه نزدیک به پردازش در نظر گرفته شود، که مستقیماً روی فابریک PCIe در کنار شتابدهندهها قرار میگیرد، به جای اینکه در ورودی/خروجی پشتی گیر کند.

این اولین ورود کیوکسیا به فلش با پهنای باند بالا نیست. این شرکت با SSDهای PCIe با برد بلند و لینکهای فلش همتا به همتای GPU، از جمله تحقیقات با انویدیا در مورد درایوهای XL-Flash تنظیم شده برای 10 میلیون IOPS، آزمایش کرده است. ترکیب این تلاشها با توسعههای جدید کارخانههای تولیدی در ژاپن — که ناشی از انتظار افزایش تقریباً سه برابری تقاضای فلش تا سال 2028 است — نشان میدهد که این نمونه اولیه یک مورد استثنایی نیست. این یک نقشه راه است که به سمت NAND نه تنها بزرگتر، بلکه سریعتر و به اندازهای سریع که نزدیکتر به پشته محاسباتی قرار گیرد، اشاره دارد.
در حال حاضر، این ماژول در مرحله نمونه اولیه باقی مانده است و سؤالات بیپاسخی وجود دارد: چگونه بارهای کاری تصادفی ترکیبی را مدیریت میکند، چگونه مقیاسبندی ECC بر تأخیر تأثیر میگذارد، و توان عملیاتی واقعی در شرایط آموزش هوش مصنوعی چگونه خواهد بود. با این حال، پیام بزرگتر در اینجا این است که فلش در حال خروج از نقش خود به عنوان ذخیرهسازی کند و عمیق و حرکت به سمت سلسله مراتب بالاتر است. اگر چشمانداز کیوکسیا (همانطور که در بیانیه مطبوعاتی آنها آمده است) محقق شود، نسل بعدی مراکز داده ممکن است ماژولهای ذخیرهسازی را در رقابت برای افتخارات پهنای باند در کنار خود پردازندههای گرافیکی ببینند.
- کولبات
- شهریور 1, 1404
- 226 بازدید






