
AMD جزئیات ساخت خط تولید محصولات خود را تنها با دو دای RDNA 4 تشریح میکند
واحدهای پردازش گرافیکی (GPU) به گونهای طراحی شدهاند که عملکرد آنها میتواند در مرحله طراحی یا حتی پس از تولید اولیه، افزایش یا کاهش یابد. سری 9000 AMD، که بر پایه RDNA 4 (معروف به Navi 4) ساخته شده، از این قاعده مستثنی نیست. AMD این موضوع را در یکی از ارائههای Hot Chips 2025 خود تأیید کرد و نشان داد که چگونه میتواند طراحی GPUهای خود را برای تولید SKUهای بیشتر کاهش دهد.
ساخت یک خانواده محصول با استفاده از دو طراحی GPU
همه GPUها شامل تعداد زیادی از اجزای مشابه هستند، از جمله واحدهای منطق حسابی (ALU)، حافظههای کش، واحدهای سختافزاری خاص منظوره، کنترلکنندهها و لایههای فیزیکی (PHY). بنابراین، اگر نقصی در طول تولید رخ دهد، بخش معیوب میتواند غیرفعال شود و پردازنده همچنان به درستی کار کند. با این حال، این به معنای انعطافپذیری کامل نیست. برخی واحدها ترانزیستورها را بین خود بازیافت میکنند و برخی دیگر به مسیرهای دادهای متکی هستند که جزء جداییناپذیر اجزای همسایه هستند. AMD ادعا میکند که RDNA 4 را به لطف ویژگیای که آن را برداشت نامتقارن (asymmetric harvesting) مینامد، سازگارتر از نسلهای قبلی خود طراحی کرده است.
با غیرفعال کردن انتخابی اجزا، میتوان تنظیماتی را در سیستمهای حافظه و تخصیص منابع نامتقارن انجام داد. این به شرکت اجازه میدهد تا GPUهای رده بالا، میانرده و تخصصی را از همان طراحی پایه یا حتی از همان دای تولید کند.



با استفاده از این استراتژی، AMD یک Navi 44 کوچکتر (سری Radeon RX 9060) را از طراحی بزرگتر Navi 48 (سری Radeon RX 9070) با کاهش تعداد موتورهای سایهزن (SE)، حافظه Infinity Cache، کنترلکنندههای GDDR6 و PHYها ایجاد کرد، اما مواردی مانند پردازنده فرمان، موتورهای نمایشگر، موتورهای رسانه، پردازنده امنیتی و سایر موارد خاص را دستنخورده باقی گذاشت. با استفاده مجدد از فوتوماسکهای Navi 48، AMD در هزینههای تولید صرفهجویی کرد. علاوه بر این، AMD کارتهای Radeon RX 9070 و RX 9070 GRE را از Radeon RX 9070 XT کامل با غیرفعال کردن عناصر خاصی ساخت که اساساً بازده را افزایش داد و آنها را قادر ساخت تا به اهداف قیمتی خود برسند. چنین رویکردی همچنین زمان عرضه GPU مربوطه به بازار را کوتاه کرد، زیرا تعداد کمتری طراحی سیلیکون منحصر به فرد نیاز به تولید اولیه، اعتبارسنجی و تولید داشت.
برداشت نامتقارن
مهمترین عنصر این استراتژی، نحوه برداشت یک موتور سایهزن (SE) است. یک SE یک بلوک ساختمانی اساسی GPU است که شامل چندین پردازنده گروه کاری (WGP)، واحدهای محاسباتی (CU) و مراحل عملکرد ثابت برای هندسه، رسترایزیشن و رندرینگ است. در محصولات مبتنی بر RDNA 4، AMD اجازه میدهد تا کل موتورهای سایهزن در صورت وجود نقص یا زمانی که هدف عملکرد پایینتری مورد نظر است، غیرفعال شوند. علاوه بر این، AMD ممکن است WGPهای خاصی را غیرفعال کند که انعطافپذیری زیادی را فراهم میکند.
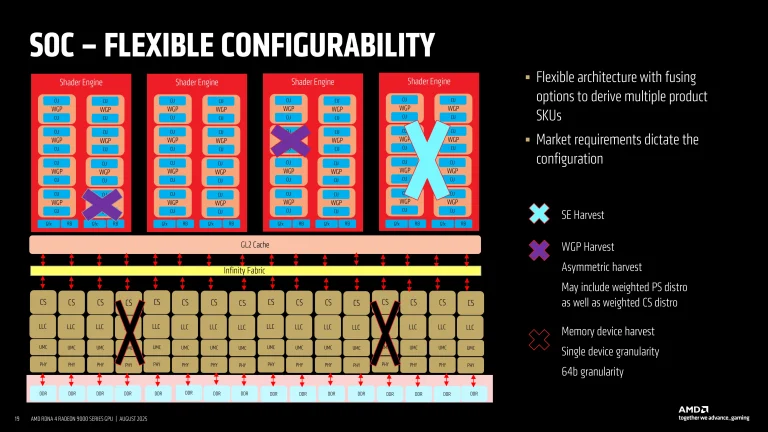
برداشت حافظه بعد دیگری از انعطافپذیری را اضافه میکند. زیرسیستم حافظه RDNA 4 شامل چندین کنترلکننده GDDR6 است که از طریق Infinity Fabric و ساختارهای کش به هم متصل شدهاند. هر کنترلکننده حافظه میتواند به صورت جداگانه غیرفعال شود، به این معنی که AMD میتواند عرض باس مؤثر را در افزایشهای 64 بیتی کاهش دهد.
به عنوان مثال، یک مدل پرچمدار مانند Radeon RX 9070 XT شامل هر چهار موتور سایهزن است که هر کدام دارای 64 واحد محاسباتی (با 4096 پردازنده جریانی که شامل ALU هستند) و چهار رابط حافظه 64 بیتی است. در همین حال، Radeon 9700 GRE رده پایینتر تنها سه SE دارد که منجر به 48 CU و 3072 SP و سه آرایه حافظه 64 بیتی میشود که در نتیجه یک رابط حافظه 192 بیتی را به همراه دارد.
علاوه بر موتورهای سایهزن کامل، مراحل برداشت کوچکتر از طریق غیرفعال کردن انتخابی پردازندههای گروه کاری در داخل یک موتور سایهزن امکانپذیر است. این کنترل دقیق به AMD امکان میدهد محصولاتی با تعداد واحدهای محاسباتی غیرمعمول، مانند Radeon RX 9070 با 56 CU، تولید کند. با استفاده از این روش، Radeon RX 9070 به جای کل SE از تعداد مشخصی CU استفاده میکند. اما همچنین با تمام رابطهای حافظه فعال عرضه میشود، بنابراین RX 9070 دارای یک باس حافظه 256 بیتی کامل است.
مفهوم برداشت نامتقارن با فعال کردن نسبتهای مختلف منابع محاسباتی به پیکسلی، بیشتر گسترش مییابد و تضمین میکند که محصولات میتوانند برای بارهای کاری بازی، وظایف چندرسانهای یا استفاده محاسباتی محور بدون بازطراحی معماری اصلی یا دای، سفارشیسازی شوند.
به عنوان مثال، Radeon RX 9070 XT یک رابط 256 بیتی کامل با شانزده گیگابایت حافظه را حفظ میکند، در حالی که RX 9070 GRE به 192 بیتی با دوازده گیگابایت کاهش مییابد. مدلهای میانرده مانند انواع RX 9060 بیشتر به باسهای 128 بیتی کاهش مییابند که بسته به SKU، از شانزده گیگابایت یا هشت گیگابایت پشتیبانی میکنند. این دقت به AMD اجازه میدهد تا به قیمتگذاری حافظه، در دسترس بودن و موقعیتیابی در بازارهای مختلف با استفاده از همان سیلیکون پایه پاسخ دهد.
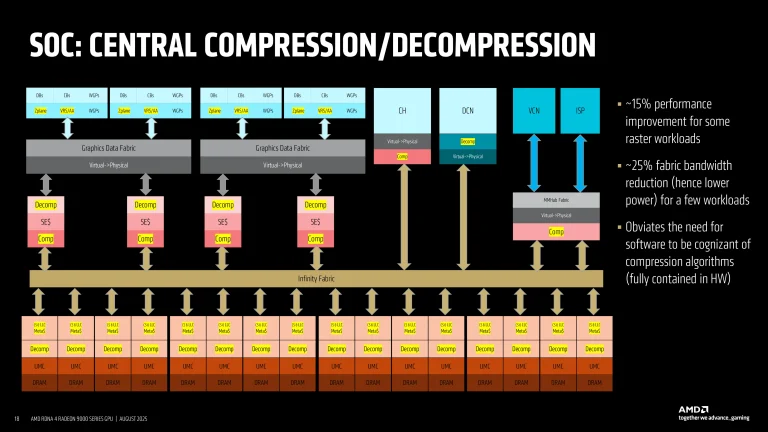
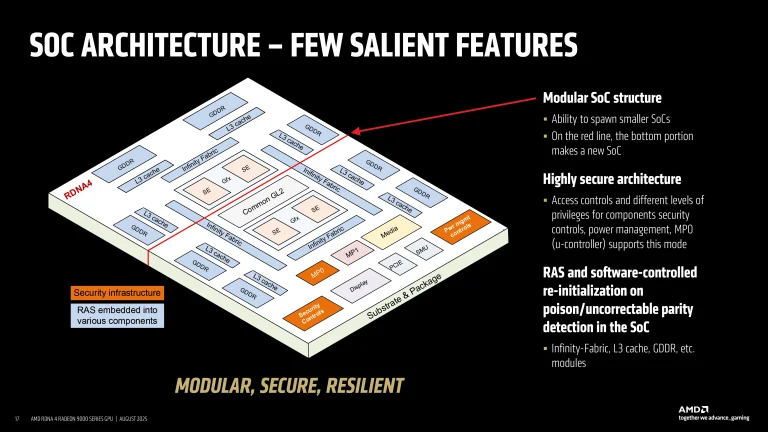
در سطح SoC، RDNA 4 بلوکهای کش L2 جهانی، سختافزار فشردهسازی و رفع فشردهسازی و لینکهای Infinity Fabric (که بسته به بار در فرکانس 1.5 گیگاهرتز تا 2.50 گیگاهرتز کار میکنند) را به صورت ماژولار یکپارچه میکند. از آنجا که این اجزا میتوانند جریانهای داده متغیر را بدون توجه به تعداد SEها یا کانالهای حافظه فعال، مدیریت کنند، معماری حتی در پیکربندیهای برداشت شده نیز کارایی را حفظ میکند.
فشردهسازی متمرکز پهنای باند و توان را در بارهای کاری مختلف صرفهجویی میکند، به طوری که AMD تا 25% کاهش در ترافیک Fabric و 15% افزایش در برخی سناریوهای رسترایزیشن را گزارش کرده است. این طراحی تضمین میکند که چه یک دای جزئی غیرفعال باشد و چه کاملاً فعال، زیرساخت پشتیبانی در سراسر آن متعادل باقی میماند.
ویژگیهای امنیتی و قابلیت اطمینان نیز در معماری گنجانده شدهاند که پیکربندی انعطافپذیر فوقالذکر را ممکن میسازد. با ارائه مدیریت خطای قوی، AMD میتواند با اطمینان تراشههای جزئی معیوب را به عنوان SKUهای رده پایینتر بدون هیچ گونه مصالحهای بفروشد.
پیامدهای تجاری
پیامدهای تجاری رویکرد برداشت نامتقارن AMD قابل توجه است: تاکنون، این شرکت خط تولیدی متشکل از هفت محصول برای رایانههای رومیزی و سرورهای استنتاج را تنها با استفاده از دو پردازنده Navi 48 و Navi 44 ساخته است. در تئوری، AMD میتوانست چهار یا بیشتر GPU RDNA 4 برای نوتبوکها را به خط تولید خود اضافه کند، اگر علاقهمند به رقابت در آن بازار بود.

متأسفانه، AMD تصمیم گرفت بازار GPUهای رده بالای دسکتاپ را با معماری RDNA 4 خود دنبال نکند. اگر یک GPU رده بالا مبتنی بر RDNA 4 (با تقویت بخش جلویی فرمان و کشهای L2 و اتصال چهار SE دیگر، و همچنین دو رابط حافظه دیگر) توسعه داده بود، میتوانست حداقل سه محصول دیگر را به خط تولید اضافه کند و به یک بازار سودآور بپردازد که ظاهراً آن را منحصراً به Nvidia واگذار کرده است.
با این حال، برداشت نامتقارن به AMD در هر دو جبهه تولید و بازاریابی کمک میکند. با گنجاندن برداشت در سطوح مختلف — از موتورهای سایهزن و پردازندههای گروه کاری گرفته تا نسبتهای محاسباتی و کانالهای حافظه — AMD خروجی هر ویفر را به حداکثر میرساند، محصولات را مطابق با نیازهای بازار میسازد و مجموعه ویژگیهای ثابتی را در سراسر خطوط تولید حفظ میکند. این امر GPUهای AMD را برای شرکت کمی سودآورتر میکند، زیرا به مدیریت هزینهها کمک میکند، چرا که تعداد دایهای قابل فروش را افزایش میدهد.
اجرای موفقیتآمیز قابلیت برداشت نامتقارن AMD، تجربه ارزشمندی را برای معماری نسل بعدی این شرکت، به نام UDNA، فراهم خواهد کرد. اینکه این موضوع چگونه بر GPUهای RDNA 5 و UDNA 6 تأثیر خواهد گذاشت، چیزی است که باید دید، پس با ما همراه باشید.
برای دریافت اخبار، تحلیلها و بررسیهای بهروز ما در فیدهای خود، در Google News را دنبال کنید. حتماً روی دکمه دنبال کردن کلیک کنید.
- کولبات
- شهریور 6, 1404
- 165 بازدید






