
مدل جدید Deepseek با تبدیل متن و اسناد به تصاویر، مصرف منابع را به شدت کاهش میدهد
توسعهدهندگان چینی هوش مصنوعی Deepseek مدل جدیدی را منتشر کردهاند که از قابلیتهای چندوجهی خود برای بهبود کارایی در پردازش اسناد پیچیده و بلوکهای بزرگ متن، با تبدیل آنها ابتدا به تصاویر، استفاده میکند، طبق گزارش SCMP. رمزگذارهای بینایی توانستند مقادیر زیادی متن را گرفته و به تصاویر تبدیل کنند که هنگام دسترسی بعدی، بین هفت تا ۲۰ برابر توکن کمتری نیاز داشتند، در حالی که سطح دقت چشمگیری را حفظ میکردند.
Deepseek هوش مصنوعی توسعهیافته چینی است که در اوایل سال ۲۰۲۵ جهان را شوکه کرد و قابلیتهایی مشابه ChatGPT از OpenAI یا Gemini از گوگل را به نمایش گذاشت، با وجود اینکه برای توسعه آن به پول و داده بسیار کمتری نیاز داشت. سازندگان از آن زمان به کار بر روی کارآمدتر کردن هوش مصنوعی ادامه دادهاند و با آخرین نسخه شناخته شده به عنوان DeepSeek-OCR (تشخیص نوری کاراکتر)، هوش مصنوعی میتواند درک چشمگیری از مقادیر زیادی داده متنی را بدون سربار توکن معمول ارائه دهد.
توسعهدهنده گفت: «از طریق DeepSeek-OCR، ما نشان دادیم که فشردهسازی بینایی-متن میتواند کاهش قابل توجهی در توکن – هفت تا ۲۰ برابر – برای مراحل مختلف زمینه تاریخی به دست آورد و مسیری امیدوارکننده را برای مدیریت محاسبات با زمینه طولانی ارائه میدهد.»
مدل جدید از دو جزء تشکیل شده است: DeepEncoder و DeepSeek3B-MoE-A570M که به عنوان رمزگشا عمل میکند. رمزگذار میتواند مقادیر زیادی داده متنی را گرفته و به تصاویر با وضوح بالا تبدیل کند، در حالی که رمزگشا به ویژه در گرفتن آن تصاویر با وضوح بالا و درک زمینه متنی درون آنها مهارت دارد، در حالی که توکنهای کمتری نسبت به حالتی که متن را مستقیماً به هوش مصنوعی وارد کنید، نیاز دارد. این کار را با تجزیه هر وظیفه به زیرشبکههای جداگانه و استفاده از کارشناسان عامل هوش مصنوعی خاص برای هدف قرار دادن هر زیرمجموعه از دادهها مدیریت میکند.
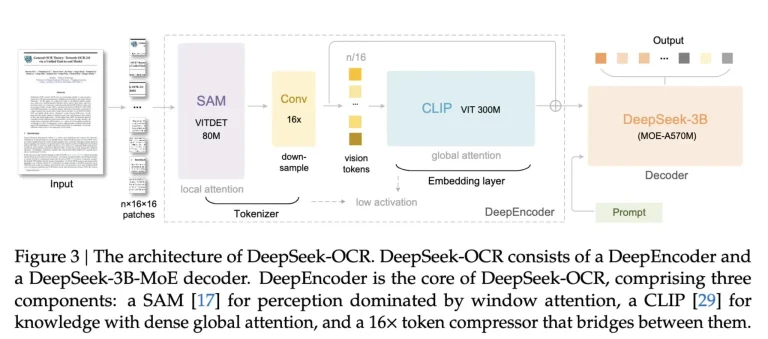
این روش برای مدیریت دادههای جدولی، نمودارها و سایر نمایشهای بصری اطلاعات بسیار خوب عمل میکند. توسعهدهندگان پیشنهاد میکنند که این میتواند کاربرد خاصی در امور مالی، علم یا پزشکی داشته باشد.
در معیارگذاری، توسعهدهندگان ادعا میکنند که هنگام کاهش تعداد توکنها با ضریب کمتر از ۱۰، DeepSeek-OCR میتواند نرخ دقت ۹۷٪ را در رمزگشایی اطلاعات حفظ کند. اگر نسبت فشردهسازی به ۲۰ برابر افزایش یابد، دقت به ۶۰٪ کاهش مییابد. این کمتر مطلوب است و نشان میدهد که بازدهی کاهشی در این فناوری وجود دارد، اما اگر نرخ دقت نزدیک به ۱۰۰٪ حتی با نرخ فشردهسازی ۱-۲ برابر نیز قابل دستیابی باشد، باز هم میتواند تفاوت بزرگی در هزینه اجرای بسیاری از جدیدترین مدلهای هوش مصنوعی ایجاد کند.
همچنین این روش به عنوان راهی برای توسعه دادههای آموزشی برای مدلهای آینده مطرح شده است، اگرچه ایجاد خطا در آن مرحله، حتی به شکل چند درصد انحراف از پایه، ایده بدی به نظر میرسد.
اگر میخواهید خودتان با این مدل کار کنید، از طریق پلتفرمهای توسعهدهنده آنلاین Hugging Face و GitHub در دسترس است.

برای دریافت آخرین اخبار، تحلیلها و بررسیهای ما در فیدهای خود، در Google News دنبال کنید، یا ما را به عنوان منبع ترجیحی خود اضافه کنید.
- کولبات
- مهر 30, 1404
- 158 بازدید






